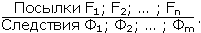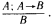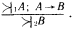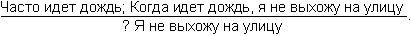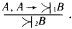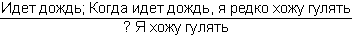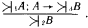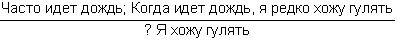"Моделирование рассуждений. Опыт анализа мыслительных актов" - читать интересную книгу автора (Поспелов Дмитрий Александрович)
Нечеткий вывод
Ранее мы говорили о кванторах общности и существования в исчислении предикатов и о близких к ним по смыслу кванторах в силлогистике Аристотеля. Эти кванторы – не единственные. Могут встречаться и более сложные указатели. И как раз их-то чаще всего используют в своих рассуждениях люди. Эти кванторы в отличие от классических кванторов будем называть квантификаторами.
Вот, например, квантификатор «только». Какова его роль в наших рассуждениях? Если кто-то говорит: «Маша из всех каш ест только гречневую», то квантификатор «только» выделяет из множества сущностей с именем «каши» одну определенную сущность. В этом случае рассматриваемый квантификатор играет роль выделителя определенной группы элементов. В другом утверждении «Только тропические страны пригодны для возделывания кофе» квантификатор «только» выполняет именно эту роль – выделителя из множества стран тех, которые относятся к тропическим. Утверждение, приведенное нами, порождает два других утверждения: «Существуют тропические страны, в которых возделывается кофе» и «Для всех стран, которые не являются тропическими, неверно утверждение, что в них можно возделывать кофе». Но в естественном языке «только» может использоваться и для указания на другие способы вычленения событий. Вот несколько примеров: «Я купил только чашки» (т.е. я купил чашки, а не что-либо иное), «На лекцию пришло только пять студентов» (т.е. именно пять, а не другое число), «Он приедет только завтра» (а не сегодня? не послезавтра?). Число подобных примеров можно неограниченно продолжать.
«Только» – не единственный экзотический квантификатор. Чего стоит, например, квантификатор «Даже»! Сравним два утверждения: «Даже Джек смог догнать эту лисицу» и «Даже Джек не смог догнать эту лисицу». Внешне оба утверждения весьма похожи. Но квантификатор «даже» выполняет в них различную роль. В первом утверждении Джек стоит на нижнем конце шкалы, по которой упорядочены все собаки, пригодные для охоты на лис, а во втором утверждении квантификатор «даже» ставит Джека на первое место в этой шкале. До настоящего времени не создана теория рассуждений с подобными квантификаторами. Поэтому в данном разделе рассмотрим лишь вполне определенную группу квантификаторов, которую будем называть нечеткими квантификаторами. Обозначим их, как это традиционно принято для кванторов в логике, перевернутыми буквами. Прежде всего определим, какие же квантификаторы будем считать нечеткими.
Их название указывает на тесную связь с новым разделом математики – нечеткой математикой. Слово «нечеткая» да еще в применении к математике вызывает законное недоумение. Но такова калька английского слова fuzzy, которое можно переводить еще как «размытая» или «расплывчатая». Именно это слово использовал Л. Заде – основатель нечеткой математики. В отличие от обычного понятия множества, известного каждому, кто сталкивался с математикой, Заде ввел понятие нечеткого множества. Оно отличается от обычного множества тем, что относительно любых его элементов в теории Заде можно сделать три утверждения, из которых только первые два рассматриваются в обычной (четкой) математике: «Элемент принадлежит данному множеству», «Элемент не принадлежит данному множеству» и «Элемент принадлежит данному множеству со степенью уверенности ?». При этом 0lt;?lt;1. Первые два утверждения соответствуют ?=1 и ?=0.
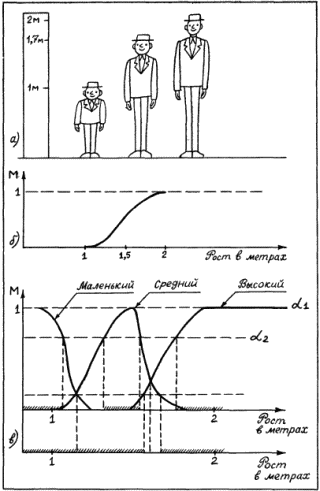
На рис. 28, а показана ситуация, связанная с формированием множества с именем «высокие люди». По-видимому, никто не усомнится, что персонаж А к этому множеству принадлежит. Для него ?=1. Столь же очевидно, что персонаж В должен остаться вне формируемого множества. Для него ?=0. Относительно же персонажа С мнения могут разделиться. Одни будут склонны считать, что рост 170 см уже достаточен для отнесения С к высоким людям. Другие же будут придерживаться противоположного мнения. Мнения относительно принадлежности отдельных элементов нечеткому множеству никогда не становятся однозначными. Это произошло бы в единственном случае, когда понятие «высокий рост» было бы регламентировано ГОСТом, обязательным для всех людей, участвующих в нашем мысленном эксперименте. А пока этого нет, каждый волен иметь по этому поводу свое мнение.
Рис. 28.
Если опросить достаточное количество людей, то можно получить усредненные характеристики того, что люди считают высоким ростом. На рис. 28, б показана некоторая функция, называемая функцией принадлежности нечеткого множества. Ее ординаты показывают степень принадлежности людей с тем или иным значением роста, отложенным по горизонтальной оси, к множеству «высокие люди». Конкретные значения ординат этой функции могут меняться при смене тех, кого мы опрашиваем (например, в Юго-Восточной Азии произойдет явное смещение границы высоких людей влево), но качественный вид функции принадлежности будет неизменным. Сначала будет идти нулевая зона, потом начнется рост значений функции, а завершением ее будет опять горизонтальный участок со значением ?=1.
«Высокий» – это представитель множества нечетких квантификаторов. Теперь можно сказать, что некоторый квантификатор является нечетким, если для него оказывается возможным построить функцию принадлежности к соответствующему нечеткому множеству. Таких квантификаторов в человеческих рассуждениях немало. Вот несколько примеров из стихотворений Б.Л. Пастернака: «Мне далекое время мерещится, дом на стороне Петербургской», «Огни заката догорали. Распутицей в бору глухом в далекий хутор на Урале тащился человек верхом», «На протяженьи многих зим я помню дни солнцеворота, и каждый был неповторим и повторялся вновь без счета». В них использованы нечеткие квантификаторы, формирующие нечеткие множества с именами «далекое время», «далекое место», «многие зимы». Для них можно построить соответствующие функции принадлежности, использовав, в частности, дополнительную информацию из текста стихотворения или из нормативных знаний о длительности человеческой жизни или об оценках расстояний, преодолеваемых верхом.
Введем важное понятие лингвистической шкалы. Лингвистическая шкала – это последовательность нечетких квантификаторов, относящихся к оценке элементов по одному и тому же основанию (расстоянию, длительности, частоте, размерам и т.п.). Примерами лингвистических шкал могут служить шкала расстояний: вплотную, очень близко, близко, ни далеко ни близко, далеко, очень далеко, в бесконечности; или шкала размеров: крошечный, очень маленький, маленький, средний, большой, очень большой, огромный. Особенностью лингвистических шкал является то, что их элементы могут быть отражены в некоторых интервалах значений определенного параметра, измеряемого в натуральных единицах (метрах, часах, квадратных километрах и т.п.). При хорошо устроенной шкале эти интервалы должны покрывать ее плотно без наложений друг на друга. Добиться этого можно путем введения отсечек на графиках функций принадлежности, фиксирующих некоторое их пороговое значение.
На рис. 28, в показаны два уровня отсечки ?: ?1 и ?2. Как видно из проекций отсекающих линий на ось абсцисс, ?1 таково, что плотного покрытия интервалами значений параметра «рост» не происходит. Между отрезками, соответствующими нечетким квантификаторам роста «маленький», «средний» и «высокий», образуются пустые отрезки (на рис. 28, в они не помечены косыми линиями). При значении ?2 заполнение почти плотное. Если оставшийся пустым отрезок разделить пополам между двумя соседними, то образуется лингвистическая шкала роста, содержащая три нечетких квантификатора. Величина ? может быть определена как степень уверенности, с которой квантификатор относит значения роста к соответствующим нечетким множествам (в нашем примере это множества «маленькие (в смысле роста) люди», «люди среднего роста» и «высокие люди»).
Перейдем теперь к нечетким рассуждениям. Напомним сначала, что один шаг достоверного вывода можно описать в виде схемы следующего вида.
Здесь над чертой стоят те утверждения, истинность которых уже доказана, а ниже черты – утверждения, истинность которых логически следует из верхних утверждений и тех правил вывода, которые используются в данной логической системе. Для большей наглядности рассмотрим один частный, но весьма распространенный случай вывода, с которым мы уже сталкивались, – по правилу модус поненс. Напомним его схему:
Рассмотрим теперь схему вида
Здесь 1 – нечеткий квантификатор, показывающий, что истинность А не является абсолютной. Конечно, вывод, который следует из подобной посылки, также не может быть достоверным. Степень его правдоподобности оценивается нечетким квантификатором 2. Примером рассуждения такого типа может служить следующая схема:
Знак вопроса стоит тут на том месте, где должен находиться некоторый нечеткий квантификатор. Интуиция подсказывает нам, что им должен быть квантификатор «часто». Вывод «часто я не выхожу на улицу» выглядит вполне в духе человеческих умозаключений.
Рассмотрим еще одну схему:
Здесь квантификатор 1 стоит в другой позиции. Примером такого рассуждения может служить следующая схема:
Какой квантификатор надо здесь подставить вместо знака вопроса? Однозначный ответ на этот вопрос вряд ли возможен. В схеме нет информации о частоте события А. А без этой информации трудно сделать сколь-нибудь содержательное заключение. Можно лишь отметить, что если речь идет о сиюминутном решении о прогулке, то положительное решение о ней имеет не слишком большую вероятность.
Рассмотрим, наконец, схему
Конкретный случай ее реализации:
Здесь определение 2 более обосновано. По-видимому, большинство читателей не будут возражать, если вместо знака вопроса будет стоять квантификатор «нередко», хотя могут быть и другие мнения.
При создании логик, моделирующих нечеткие рассуждения, делалось немало попыток поиска формальных процедур, позволяющих «вычислять» вид 2. О некоторых из них говорится в комментариях к данному разделу. В следующем разделе мы опишем один из возможных способов такого «вычисления», а в заключительном разделе главы познакомимся еще с несколькими предложениями такого рода. Но прежде чем делать это, остановимся еще на одном моменте, связанном с использованием нечетких квантификаторов при рассуждениях.
В высказываниях «В Ленинграде часто идет дождь» или «Мой ребенок часто болеет» использован один и тот же нечеткий квантификатор «часто». Но каждому ясно, что за ним скрывается неодинаковая фактическая частота. Дожди в Ленинграде, наверное, идут куда чаще, чем болеет ребенок. Один и тот же квантификатор соотносится в этих высказываниях с различными нормами. Норма частоты дождя в Ленинграде иная, чем норма частоты заболевания детей. Если житель Москвы говорит, что он живет недалеко от работы, а житель Ялты говорит то же самое, то за квантификатором «недалеко» у москвича скрывается куда большее расстояние, чем у ялтинца. Таким образом, сами по себе квантификаторы ничего не определяют, кроме положения на лингвистической шкале. В конкретных ситуациях они приобретают некоторый физический смысл, зависящий от этих ситуаций. Поэтому особое значение приобретают исследования, в которых предлагается аппарат, позволяющий делать нечеткие выводы единообразным способом для всего класса однотипных или похожих ситуаций.
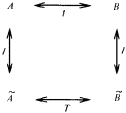
Известен, например, Принцип ситуативной инвариантности, позволяющий, проведя рассуждение для одной ситуации, преобразовывать его формальным образом для ситуаций, сходных с первоначальной. Этот принцип срабатывает, если имеется лингвистическая шкала. Тогда переход от ситуации к ситуации связан с монотонным смещением всех отрезков, соответствующих квантификаторам шкалы, на определенное число позиций влево или вправо по множеству значений признака, учитываемого данной лингвистической шкалой. Такое смещение позволяет использовать в нечетких рассуждениях элементы, характерные для рассуждений по аналогии. Только вместо диаграммы, отражающей пропорцию Лейбница, в нечетких рассуждениях появляется нечеткая диаграмма моделирования (НДМ), которая имеет вид
В этой диаграмме А обозначает описание некоторой ситуации, а ? – отображение этой ситуации с помощью перехода от качественных параметров, присутствующих в описании А, к их представлению через утверждения с нечеткими квантификаторами. Таким образом, ? есть нечеткая модель ситуации А. Если ситуация А является основанием для перехода с помощью некоторого рассуждения Т к ситуации B, то нам бы хотелось, чтобы существовало нечеткое рассуждение , с помощью которого из ? получалось бы описание , и между А и ?, а также между В и существовало определенное соответствие I (например, изоморфизм). Диаграмма НДМ должна обладать свойством коммутативности. Другими словами, должно получаться одинаковым, если сначала проводится четкое рассуждение Т, а затем от В происходит переход с помощью соответствия I к или если сначала от А совершается переход к ?, а затем проводится нечеткое рассуждение , аналогичное рассуждению Т.
Такая близость рассуждений по аналогии и нечетких рассуждений не случайна. Ибо в основе этих рассуждений лежит идея сходства, похожести.