"DirectX 8. Начинаем работу с DirectX Graphics" - читать интересную книгу автора (, Ваткин Сергей, Dempski Kelly, Watson Johnny, Поздняков...)
#2: Оптимизация Direct3D приложений
Начнем, как обычно, издалека. Оптимизация любого приложения, а графического тем более, это процесс не только увлекательный и волнующий, но очень и очень полезный. Затратив немного усилий в момент, когда создается приложение можно избавить себя от кучи проблем в момент, когда приложению понадобится дополнительная производительность. К тому же, обычно, если программист задумывается об оптимизации, то у него есть немного время, и он может написать не только быстро, но и красиво. Большая часть советов, приводимых здесь общедоступна, но, к сожалению, не общеизвестна. А, учитывая, что чем больше хороших игровых проектов (это особенно актуально для России), тем больше платят зарубежные издатели за права на издание, тем больше в конечном итоге объем рынка игровых приложений в России, и тем привлекательнее этот рынок для инвестиций. Замкнутый круг, от расширения (но не разрыва), которого выигрывают все стороны — повышается престиж страны и конечный заработок разработчиков. Итак, немного напыщенных фраз закончены — пора перейти к советам.
Статья не ставит своей целью разработку качественного каркаса для графического движка современного уровня, а просто призвана объяснить и по возможности обосновать тонкие места и ошибки в большинстве современных разработок.
Оптимизация трехмерного приложения может вестись по нескольким ключевым позициям:
1. Оптимизация рендеринга.
2. Оптимизация процессорной части приложения.
3. Оптимизация алгоритмов.
Такой порядок обычно считается направлением, в котором оптимизируется приложение. Программисты с энтузиазмом берутся оптимизировать графическое ядро, в нем, естественно, вязнут (оптимизация — процесс итерационный, а потому бесконечный, к тому же переходить ко второму пункту не хочется, а про третий вообще стараются забыть). Но это обусловлено не отдачей от каждой конкретной части, а скорее нежеланием программистов думать о сложном и высоком, обращать внимание на мелкие детали и тщательно следить за качеством кода. Хотя математики давно знают, что никакое улучшение аппаратуры не может сравниться с оптимизацией (улучшением существующих, разработкой новых) алгоритмов. Оптимизация процессорной части важна, поскольку большинство приложений ограничиваются процессором и выигрыш в скорости расчета процессором специфических функций (начиная от поиска пути и заканчивая графикой) напрямую увеличивает производительность приложения. Графическая подсистема постоянно улучшается, но пределы производительности практически достигнуты и скоро будет произведена замена существующих способов рисования сцены новыми. Поэтому оптимизация графического ядра, это вещь важная, но не стоит уделять ей внимания больше, чем она того заслуживает (это относится только к Direct3D программистам).
Рассмотрим их по порядку, причем начнем с конца.
Мы интересуемся только графической частью приложения, поэтому здесь главное правило, как и в программировании:
Если можно что-то сделать вне цикла — делай это вне цикла.
Если можешь создать таблицу с параметрами и ее использовать — создай и используй.
Если можешь что-то не считать — не считай это.
А главное, если есть возможность что-то ускорить, то эту возможность нельзя упускать.
Создание таблицы синусов и косинусов для быстрого преобразования Фурье (задачи распознавания образов и шифрования), вместо использования функций позволяет увеличить скорость расчета на порядки.
Если можно обновлять информацию не для каждого фрейма, а хотя бы для каждого второго, то рост производительности в этой части будет на 100%.
Если используются функции (для сглаживания пути или формирования волн на воде), то создание таблиц значений и интерполяция между ними может дать значительный прирост. Если вершина не попала на экран ее можно смело не рисовать (здесь нужна аккуратность — быстрый алгоритм отсечения и невидимые полигоны на сцене предпочтительнее, чем ни одного лишнего и чистый qsort для сортировки). С сортировкой вообще нужно быть осторожным — мы не можем предсказать разброс значений в массиве, а значит, не можем предсказать время выполнения сортировки методами типа "разделяй и властвуй" (qsort), поэтому возможен предварительный разброс значений и последующая быстрая сортировка, или сортировка маленьких массивов методами типа "Пузырек" (все знают как плохо работает qsort в случае обратной упорядоченности массива или массива с большим количеством повторяющихся значений).
Интересно, что для этой части предлагаются только методы оптимизации выполнения на уровне аппаратуры, но забывать про оптимизацию параллельности выполнения тоже не стоит. Мы имеет не один процессор, а два: CPU и GPU. В GPU работа хорошо распараллеливается, и мы за ней не следим, но есть ряд операций, выполнение которых заставляет процессор простаивать, поэтому ТАКИЕ операции нужно стараться уменьшать в количестве и следовать рекомендациям, приведенным в части статьи, посвященной непосредственно примерам. Кстати в этом процессе может помочь Statistical Driver от NVIDIA, но его нужно получать непосредственно от NVIDIA, а для этого необходимо стать регистрированным разработчиком на developer.nvidia.com.
Итак, самое главное
1 удаляем непосредственное преобразование типа float к типу long или int.
Каждый раз, когда вы пишите
int i = f; // f - float, вы неявно вызываете функцию ftol() или ftoi(), поэтому лучше так:
Вместо:
int i = f; // вызов __ftoi()
Пишем:
__inline void myftol(int *i, float f) {
__asm fld f;
__asm mov edx, I
__asm fistp[edx];
}
//…
MyFtoL(amp;i, f);
Либо используем недокументированный переключатель оптимизации /QIfist чтобы избежать вызовов __ftol().
2 Не используем fsqrt — 79 циклов это слишком долго.
Достаточно качественная реализация приведена в NVToolkit (MUST HAVE для всех кто программирует графику, но не хочет лезть в математику). Полный архив NVToolkit можно скачать с http://developer.nvidia.com/. Когда я ее выкачивал он лежал по адресу http://developer.nvidia.com/docs/IO/1208/ATT/NVTK_no_libs.zip.
/********************************************************************* ulSqrt.cpp
Copyright (C) 1999, 2000 NVIDIA Corporation
This file is provided without support, instruction, or implied warranty of any kind.
NVIDIA makes no guarantee of its fitness for a particular purpose and is not liable under any circumstances for any damages or loss whatsoever arising from the use or inability to use this file or items derived from it.
Comments:
*********************************************************************/
#include lt;stdio.hgt;
#include lt;math.hgt;
#include lt;windows.hgt;
static float _0_47 = 0.47f;
static float _1_47 = 1.47f;
float__fastcall ulrsqrt(float x) {
DWORD y;
float r;
_asm {
mov eax, 07F000000h+03F800000h // (ONE_AS_INTEGERlt;lt;1) + ONE_AS_INTEGER
sub eax, x
sar eax, 1
mov y, eax // y
fld _0_47 // 0.47
fmul DWORD PTR x // x*0.47
fld DWORD PTR y
fld st(0) // y y x*0.47
fmul st(0), st(1) // y*y y x*0.47
fld _1_47 // 1.47 y*y y x*0.47
fxch st(3) // x*0.47 y*y y 1.47
fmulp st(1), st(0) // x*0.47*y*y y 1.47
fsubp st(2), st(0) // y 1.47-x*0.47*y*y
fmulp st(1), st(0) // result
fstp y
and y, 07FFFFFFFh
}
r = *( float *)amp;y;
// optional
r = (3.0f - x * (r * r)) * r * 0.5f; // remove for low accuracy
return r;
}
/*
sqrt(x) = x / sqrt(x)
*/
float __fastcall ulsqrt(float x) {
return x * ulrsqrt(x);
}
3 Нормализация векторов. Обычно делают неправильно, но сначала код:
//Обычно делают так:
void normaliseNormalise(Vector *v) {
float L, L_squared, one_over_L;
L_squared = (v-gt;x * v-gt;x) + (v-gt;y * v-gt;y) + (v-gt;z * v-gt;z);
L = sqrt(L_squared);
one_over_L = 1.0 / L;
v-gt;x = v-gt;x * one_over_L;
v-gt;y = v-gt;y * one_over_L;
v-gt;z = v-gt;z * one_over_L;
}
// А можно так:
#define ONE_AS_INTEGER ((DWORD)(0x3F800000))
float __fastcall InvSqrt(const float amp; x) {
DWORD tmp = ((ONE_AS_INTEGER lt;lt; 1) + ONE_AS_INTEGER - *(DWORD*)amp;x) gt;gt; 1;
float y = *(float*)amp;tmp;
return y * (1.47f - 0.47f * x * y * y);
}
void Normalise(Vector *v) {
float L_squared, one_over_L;
L_squared = (v-gt;x * v-gt;x) + (v-gt;y * v-gt;y) + (v-gt;z * v-gt;z);
one_over_L = InvSqrt(L_squared);
v-gt;x = v-gt;x * one_over_L;
v-gt;y = v-gt;y * one_over_L;
v-gt;z = v-gt;z * one_over_L;
}
По-моему комментарии излишни :).
4 Разворачивание циклов
Обычно циклы разворачиваются. Наша цель максимально эффективно использовать кэш процессора, поэтому слишком глубокого разворачивания не нужно, достаточно повторений в цикле.
Для этого используем макросы, но оставляем возможность переключится на функции и не развернутые циклы для отладки (Отладка развернутых циклов сложна и неинформативна).
Опасайтесь разбухания кода!
Измеряйте производительность кода постоянно, причем желательно вести базу данных, в которой будут указываться не только изменения в коде, но и изменения в производительности. Особенно такие базы полезны при работе с несколькими программистами графического ядра приложения.
Благодатная тема для описания, существует огромное количество способов сделать неправильно и один способ сделать правильно (Это заявление не относится к операционной системе Windows, для нее правильнее другое: Существует огромное количество способов сделать правильно, но они устарели и их лучше не использовать, а самый лучший способ — это как раз тот, в который мы недавно добавили большое количество NOP'ов и он работает как раз так, чтобы чуть-чуть тормозить на средней системе :)).
DirectX 8 и, в частности, Direct3D8 - это безусловно самая лучшая разработка Корпорации (ведь мы уже смело можем ТАК ее называть).
Итак, следуйте следующим указаниям:
1. Не используйте "тяжелые" функции в цикле рендеринга. Всегда функции
ValidateDevice(), CreateVB(), CreateIB(), DestroyVB(), Optimize(), Clone(), CreateStateBlock(), AssembleVertexShader()
помещайте в загрузку сцены и НИКОГДА в цикл рендеринга приложения. Создание буфера вершин может занять до 100 ms!
2. Использование DrawPrimitiveUP() является ошибкой, вызывает задержки в работе процессора и всегда вызывает дополнительное копирование вершин.
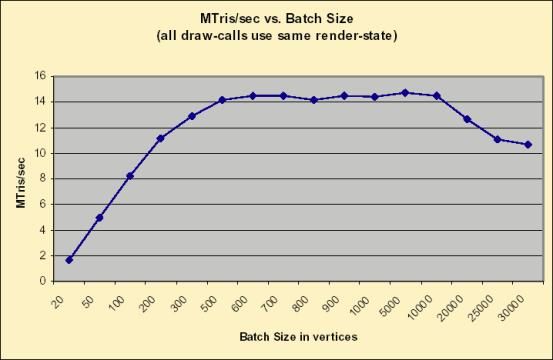
3. Не позволяйте художникам контролировать ваш код. Если вам необходимо рисовать по 200+ вершин за проход, то геометрия должна удовлетворять этому требованию. Позволите себе рисовать по 2 вершины за вызов — и вы ТРУП :(.
4. Сортируйте по текстурам и по шейдерам. Если сложно сортировать по обоим параметрам, используйте кэширование. Создаем большую текстуру 4K#215;4K, в нее копируем текстуры, используемые в сцене, подправляем текстурные координаты геометрии и рисуем большой кусок с одной текстурой сортированный по шейдерам. Либо готовим геометрию таким образом, чтобы это кэширование не требовалось.
5. Стараемся использовать как можно меньшее количество буферов вершин. Смена буфера очень "тяжелая" операция и дорого нам стоит. Поэтому
6. Загружаем модели в сцене в минимальное количество буферов.
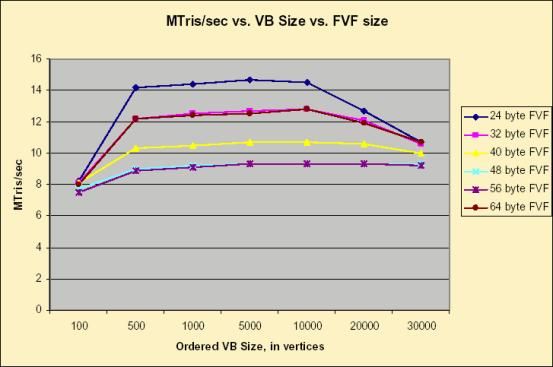
7. Используем минимальное количество разновидностей FVF, если возможно — то один общий FVF (Максимального размера).
8. Доступ к буферу асинхронный, поэтому мы можем одновременно рисовать модель из одной части буфера и изменять значения в другой.
9. Всегда считайте данные в видеокарте, как доступные только для записи.
10. Если вам необходимо восстанавливать состояние буфера, храните две копии.
11. Если вы обновляете данные в буфере каждый фрейм, используйте динамические буферы вершин.
12. Старайтесь вместо динамического буфера использовать статический буфер, анимированный шейдером.
13. Разделяйте буфер на потоки, если вам необходимо обновлять только часть информации, и.
14. Всегда обновляйте данные подряд. (процессор передает данные по 32 байта, 64 байта — Pentium IV).
15. Старайтесь использовать кэш вершин видеокарты. Если данные в кэше они не пересчитываются (экономится Tamp;L шаг).
16. Всегда старайтесь использовать FVF кратный 32 байтам.
17. Не используйте примитивы высокого уровня — NVIDIA признает, что это рекламный ход и рекомендует подождать карт смещения (Displacement maps в DirectX9).
18. Производите грубое отсечение частей, не попадающих на экран, и не посылайте их в видеокарту (CPU или ProcessVertices).
19. Рисуйте за раз не менее, чем по 200+ вершин. См. иллюстрации в конце статьи.
20. Всегда используйте индексированный рендеринг. Это единственный случай, когда используется кэширование в кэш вершин видеокарты.
21. Отдавайте предпочтение Indexed Strips, после этого Indexed Lists, после этого Indexed Fans. Грамотное использование Indexed Strips может дать большой прирост скорости (кэш + отсутствие копирования лишней информации). Размер кэша — 18 вершин для GeForce 3/4 Ti, 10 — для GeForce 1/2/4 MX.
22. Для многопроходного рендеринга используйте первый Z-only проход — это экономит расчет следующих проходов.
23. Используйте уровни детализации для всего, чего только возможно — для текстур (для удаленных объектов можно не накладывать Detailed Map), для объектов в части геометрии (количество полигонов) и скиннинга (уменьшаем количество костей (bones) при удалении объекта), отключаем дальние источники освещения, отключаем туман для объектов, на которых он не сказывается.
24. Всегда отдавайте предпочтение большему разрешению перед FSAA (Full Scene Antialiasing) — это бесплатный антиалиазинг.
25. Попробуйте уменьшить размер вершины. Например, позволяйте вершинным шейдерам генерировать компоненты вершины. Сжимайте компоненты и используйте вершинные шейдеры для декомпрессии.
26. Перемещайте вершины в буфере, для того чтобы они использовались подряд при обработке треугольников.
27. Не используйте пару функций BeginScene(), EndScene() более одного раза на кадр.
 |
 |
На этом мы закончим общую часть, если вам стало интересно — прекрасно, значит я достиг своей цели. Дополнительная информация может быть найдена на сайте http://developer.nvidia.com/
Следующая статья будет посвящена созданию рабочего каркаса игрового графического движка.
Пишите — мне интересно Ваше мнение, Ваши предложения и Ваши комментарии. В споре рождается истина и разбиваются головы.
| © 2024 Библиотека RealLib.org (support [a t] reallib.org) |