"Тайны и секреты компьютера" - читать интересную книгу автора (Орлов Антон)
Глава 13. дНАПН ОНФЮКНБЮРЭ, или о проблемах понимания русского языка…
Строчки, подобные той, что вас так привлекла в заголовке, наверняка иногда встречались вам в путешествиях по Интернету или при чтении электронной почты. Как вы наверняка знаете, такое возникает из-за неправильно подобранной кодировки для чтения текста, — в Internet Explorer даже есть меню специальное: Вид-Вид кодировки (если использовать пятую версию, а в более старых может быть и в других меню). Вы также наверняка пробовали открывать в программах для Windows файлы с текстом, созданные в старых программах для Dos, например, набранные в Norton Editor, и почти всегда возникало затруднение с их чтением: текст отображался примерно так, как на рис. 13.1, и что-либо понять было просто невозможно.
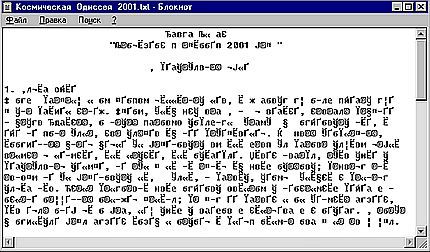 |
Рис. 13.1.
В чем же тут дело? Что такое «кодировка»? Почему их столько много, и все они разные? И, наконец, каким образом можно решить их проблему — не запускать же каждый раз Norton Editor, чтобы прочитать и напечатать свои старые файлы?
Кодовая страница
Как вы наверняка знаете, в компьютерных технологиях для записи текстовой информации используется кодирование символов последовательностями из восьми бит — одного байта.[28] Один байт соответствует одному символу. Иными словами, для записи одной буквы, цифры или значка применяется последовательность из восьми нулей и единиц.
Когда компьютерная программа получает из какого-нибудь источника компьютерные же данные, в которых содержится текст (читает текстовый файл с диска, с CD-ROM'а, получает текст из Интернета), то она выделяет из получаемого массива данных последовательности по восемь бит и воспринимает их как байты. Каждому байту, то есть каждой последовательности из восьми нулей и единиц соответствует определенный символ. Какой же конкретно? А вот это узнается программой из так называемой "таблицы символов", которая знакома абсолютно каждой программе, могущей отображать текст и используется программой для такого отображения.
Таблица символов (еще она называется "кодовой страницей") — это набор данных для перевода последовательностей бит в символы. Она может либо храниться в самой программе, либо в компонентах операционной системы и «поставляться» программе при запросе из нее. Получив последовательность из восьми бит, программа смотрит в таблицу символов и определяет из нее, какому символу эта последовательность бит соответствует. После этого программа использует дальше именно этот символ — например, отображает его на экране, чтобы пользователь мог читать текст.
Нетрудно понять, что таблица символов должна быть строжайшим стандартом — ведь если текст был написан его автором в программе, которая переводит его в последовательность бит в соответствии с одной таблицей символов, а пользователь читает эту последовательность другой программой, которая переводит эту последовательность бит в отображаемые на экране символы в соответствии с данными другой кодовой страницы, то прочитать такой текст сможет только человек, долгие годы прослуживший в шифровальном отделении внешней разведки. И для английского алфавита (латиницы) это действительно так — во всех существующих таблицах символов, использующихся во всех имеющихся компьютерных программах каждая латинская буква кодируется одной и только одной, твердо и строго определенной международными стандартами последовательностью бит — байтом. Такое соответствие последовательностей бит и отображаемых символов разработано почти двадцать лет назад на основе последовательности букв в латинском алфавите.
Каждая последовательность восьми бит имеет также и свое числовое значение — это ведь фактически число в двоичной системе счисления, которое нетрудно перевести в десятичную. Например, 01010101 в двоичной системе счисления — это 85 в десятичной, а в соответствии с международными стандартами эта последовательность бит кодирует символ «U». Число 85 в данном случае называется кодом символа «U». То есть можно сказать, что при отображении текстовых данных программа, отображающая их, каждую последовательности восьми бит воспринимает как число — код символа, смотрит в таблице символов, кодом какого символа это число является и отображает именно этот символ. Таблицу символов можно отобразить визуально — например, в Windows этой цели служит программа "Таблица символов." При таком отображении символы расставляются по возрастанию их кодов.
Но с помощью восьми бит можно закодировать до 256 символов — в самом деле, каждый бит может иметь значение 0 или 1, то есть одно из двух, следовательно, всего различных восьмибитовых последовательностей может быть 2*2*2*2*2*2*2*2=28=256. Английских букв — 26, их же, но заглавных — столько же, цифры и служебные символы вроде запятой, точки займут еще ну, мест 50, если по максимуму. Поэтому для возможности адаптации операционных систем к различным другим алфавитным системам (то есть, в применении к русскому языку, русификации программ[29]) в качестве строгого международного стандарта было принято строгое соответствие отображаемым символам лишь первых 127 последовательностей восьми бит — то есть первой половины кодовой страницы, а вторую половину отдали "на откуп" производителям регионального программного обеспечения и информационных ресурсов — чтобы они размещали в ней свои алфавиты.
 |
Рис. 13.2.
Узаконенные международными стандартами коды первых 127 символов кодовых страниц, которые должны быть едиными во всех таких страницах, получили название "стандарта ASCII". Эти символы также могут кодироваться всего семью битами информации. Первые 32 кода (от 0 до 31) были назначены управляющим символам (например, символ с кодом 13 — это символ конца абзаца), остальные кодировали строчные и прописные латинские буквы, цифры, знаки препинания и математических операций. Коды второй половины этой 256-символьной кодовой страницы получили название "расширенного стандарта ASCII". Ими кодировались, как уже было сказано выше, национальные алфавиты, а также символы псевдографики, математические и некоторые другие символы. Первый бит кода символа второй половины кодовой страницы имел значение «1», в то время как для первой половины он равнялся «0». Вы можете легко отобразить на экране символ с желаемым кодом, набрав, например, в Word его код (десятичный на цифровой клавиатуре, с нулем вначале) при удерживаемой клавише Alt.
Поэтому появились различные версии кодовых страниц (различающиеся именно своей второй половиной), которым были присвоены некоторые номера для отличия их друг от друга. Чтобы пустое место в исходной английской кодовой странице не пропадало, в ней на места, соответствующие кодам символов больше 127, были поставлены гласные буквы английского алфавита с надстрочными знаками, использующимися в некоторых европейских языках вроде французского для обозначения по особому произносящихся букв, а также символы, позволяющие в текстовом режиме создавать простейшие графические изображения — символы псевдографики. В региональных кодовых страницах на этих местах стали располагать символы отличных от английского алфавитов, таких, как русский, турецкий, вьетнамский, тайский и т. д. Программы, создаваемые в неанглоязычных странах, были рассчитаны на работу с такими кодовыми страницами и, получая откуда-нибудь код символа, больший 127, отображали тот символ, который стоял под таким номером именно в их региональной кодовой странице, а не в исходной английской. Для ввода текстовой информации производились специальные наклейки на клавиатуру, а сейчас делаются и «локализованные» клавиатуры — с выгравированными на них символами национальных алфавитов. При поступлении с клавиатуры в программу, работающую с текстом, символа с кодом, большим 127, программа записывала в файл его код так, как он поступил, а вот отображала символ в соответствии с кодовой страницей.
Код такого символа передавался в программу драйвером клавиатуры, когда был включен специальный режим — "переключена раскладка". В таком режиме при нажатии какой-нибудь клавиши с символом драйвер передавал в программу не код собственно нажатой клавиши, а код, соответствующий в региональной кодовой странице тому символу, который был помещен на этой клавише при «локализации» клавиатуры, то есть гравировке или наклейке на ее кнопки символов неанглийского алфавита.
Иными словами, кодовая страница — это как бы «закон» для программы, работающей с вводом-выводом текстовой информации, регламентирующий, как должно интерпретировать и выводить на экран или печать последовательность бит, являющуюся записью текста, а также как должно воспринимать ввод данных с клавиатуры. В разных странах существуют разные законы, но первые части у всех законов общие, а поэтому одинаковые.
Российская особенность
В большинстве стран была создана одна кодовая страница для своего алфавита. Но в России были некоторые особенности.
Изначальные английские версии поставляемых в Россию программ не могли работать с русским алфавитом (это и ясно — в них же не было русской кодовой страницы). Поэтому была создана русская кодовая страница ISO-8859-5, в которой кодам символов, большим 127, соответствовали русские буквы. Так как их всего 33, а с заглавными — 66, то в кодовой странице осталось место для символов псевдографики. Для того, чтобы с этой кодовой страницей можно было работать, имелось три возможности: писать программы, отображающие символы именно в соответствии с ней; создать операционную систему, которая сама будет «заведовать» вводом и выводом текста в соответствии с нужной кодовой страницей, а программы будут лишь использовать готовый результат; создать специальную программу, которая будет работать вместе с операционной системой и обрабатывать ввод и вывод текстовой информации в соответствии с нужной кодовой страницей. Первая возможность из-за своей сложности использовалась мало, третья подразумевала создание и использование специальных программ — русификаторов, которые долгое время использовались, при использовании второй возможности была необходима русификация или локализация операционной системы — то есть внедрение в нее функций отображения символов в соответствии с заданной кодовой страницей. В настоящее время повсеместно применяются локализованные операционные системы, то есть те, в которых кроме внедрения функций работы с русской кодовой страницей еще и переведен интерфейс.
Вариантов русской кодовой страницы было два. Один, вышеупомянутый — ISO-8859-5. Другой, так называемый «альтернативный», отличался от него другим порядком следования русских букв до строчной «р» и имел ту особенность, что символы псевдографики кодировались в нем теми же кодами, что и в исходной английской таблице символов, а следовательно, при принятом в операционой системе этом варианте кодовой страницы можно было использовать нелокализованные версии западных программ, работающих с псевдографикой. Например, западная программа могла из символов псевдографики изобразить таблицу. Она считывала из файла код символа и отображала на экране соответствующий ему значок. Если в системе была установлена «альтернативная» кодовая страница, то это оказывался именно символ псевдографики и рисунок получался. Если же в системе стояла ISO-8859-5, то рисовалась русская буква, и внешний вид рисунка был весьма своеобразным. Поэтому несмотря на то, что в «альтернативной» кодовой странице русские символы шли не подряд, а с разрывом между строчными буквами «п» и «р», именно она впоследствии получила наибольшее распространение. Кодовая страница ISO-8859-5 применялась при русификации компьютерных систем Sun, поставлявшихся в Россию.
Заслуга внедрения русских кодовых страниц принадлежит российской компании «Диалог» и ее ведущему программисту Петру Квитеку. В 1989 году в этой фирме — партнере Microsoft была локализована MS-DOS 4.1, первой среди всех операционных систем. При ее создании в качестве основной кодовой страницы была взята «альтернативная» кодировка, названная Dos(866), — именно из-за того, что программы, использующие ее, корректно отображали символы псевдографики. Это привело к еще более широкому распространению данной кодовой страницы, так как MS-DOS была основной операционной системой для персональных компьютеров.
При создании локализованной версии операционной системы Windows фирма Microsoft решила изменить ставшую общепринятой русскую кодовую страницу Dos(866). В частности, с появлением графического интерфейса отпала необходимость в использовании символов псевдографики, что позволило сделать порядок символов русского алфавита в кодовой странице в соответствии с алфавитной последовательностью, а также разместить в ней различные специальные символы вроде изображения торговой марки — ™. Появилась кодировка Windows-1251, которую создал тот же Петр Квитек. В ней тем символам, что в кодировке Dos(866) соответствовали одни русские буквы, были поставлены в соответствие другие символы. В результате для чтения в Windows русского текста, набранного в Dos, стали требоваться программы-перекодировщики.
Шрифты
"Носителями" кодовых страниц в Windows являются шрифты. Каждый шрифт — это фактически как бы отдельная кодовая страница, в которой записана информация о внешнем виде отображаемых символов, их дизайну, графике и соответствии каждого графического изображения символа определенному коду. С помощью программы Windows "Таблица символов" можно посмотреть первые 256 символов, могущих быть отображенными с помощью данного шрифта. Это могут быть как символы, соответствующие кодовой странице Windows-1251 и применяемые для отображения текста, так и значки для «разукрашивания» текстового документа, хранящиеся в специальных символьных шрифтах или даже математические символы (рис. 13.3).
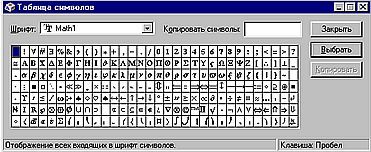 |
Рис. 13.3.
Практически все текстовые редакторы под Windows, кроме разве что Блокнота, дают возможность пользователю выбирать желаемый шрифт для его текста. Текст, набранный с помощью обычного шрифта, например, Ms Serif, будучи оформлен шрифтом символьным вроде Wingdings, превратится в набор символов: "#237;#224;#225;#238;#240;#241;#232;#236;#226;#238;#235;#238;#226;", так как в этом шрифте на местах, соответствующих кодам символов русских букв, расположены графические картинки стрелок.
Unicode
В ранних версиях Windows для каждой кодовой страницы должен был иметься свой шрифт, так как в один шрифт — в одну кодовую страницу — нельзя было поместить больше 255 символов. Это имело определенные неудобства, и был придуман и утвержден новый стандарт таблицы символов — Unicode. Согласно этому стандарту каждый символ кодировался не восемью, а шестнадцатью битами информации, что позволяло закодировать до 65536 символов. Эта кодировка также получила название двухбайтовой кодировки. Для совместимости со старыми стандартами первые 256 символов стандарта Unicode соответствовали стандартной кодовой таблице, а на остальных местах можно было разместить все необходимые символы всех языков. Были созданы новые шрифты в стандарте Unicode. Безусловно, использовались в них далеко не все 65 тысяч символов — стандарт имеет большой задел на будущее, и пока в шрифтах, совместимых с этим стандартом, «заняты» только первые сотни мест.
В шрифте Unicode имеется как бы несколько кодовых страниц сразу. Вот, к примеру, состав Unicode-шрифта Times New Roman (рис. 13.4).
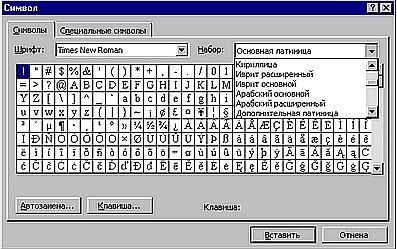 |
Рис. 13.4.
Вы видите в правом углу диалогового окна Word "Вставка символа" список региональных кодовых страниц, представленных в этом шрифте. Для того, чтобы программы, не поддерживающие стандарт Unicode (например, Microsoft Word 6.0), могли работать с такими шрифтами, операционная система осуществляет так называемую "подстановку шрифтов", то есть «раскладывает» шрифт Unicode на отдельные кодовые страницы и выбирает из него ту страницу, которая соответствует установленной в системе. Параметры подстановки прописываются в системном реестре, а в операционных системах Windows9x — и в файле Win.ini (рис. 13.5).
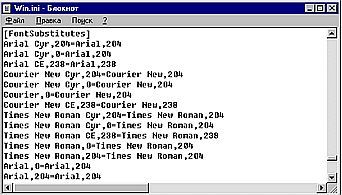 |
Рис. 13.5.
Смысл находящихся в системном реестре и в файле win.ini выражений — указание программам на то, где в шрифте искать символы, соответствующие нужной кодовой странице. Так, для шрифта Times New Roman эти символы (кириллица) начинаются с 204-го места, что и указано в Win.ini. Теперь Microsoft Word 6.0 спокойно будет работать с Unicode — шрифтом Times New Roman, воспринимая его как обычный кириллический шрифт. При этом в восприятии этого текстового редактора шрифт Times New Roman окажется как бы «разложенным» на набор шрифтов (Times New Roman Cyr, Times New Roman CE и др.), каждый из которых будет соответствовать определенной кодовой странице, несмотря на то, что все эти «шрифты» хранятся в одном файле.
Иногда встречается ситуация, когда Microsoft Word 97 вполне нормально отображает на экране текст, но на принтер выводится набор квадратиков. Это вот как раз проявляется некорректное взаимодействие программного обеспечения, когда одни компоненты (Word97) поддерживают новый стандарт, а другие (драйвера к принтеру) — нет.[30]
Существуют русские шрифты, полностью совместимые с стандартом Unicode, которые без проблем отображаются и печатаются как в старых, так и в новых программах. Они содержат только стандартный набор символов, соответствующий русской кодовой странице и отличаются еще красивым их дизайном. В выпадающем меню выбора шрифта они обычно имеют префикс «a_» (рис. 13.6).
 |
Рис. 13.6.
Koi-8
В то время как на рынке операционных систем для персональных компьютеров безоговорочную победу одержала всем нам знакомая MS-DOS, среди операционных систем для сетей дело обстояло не так. Там начинала властвовать Unix — операционная система, построенная на несколько других принципах. Эта система имела открытый исходный код — любой программист мог создать «свою» Unix, настроенную именно на его предпочтения, была очень удобна для программирования. И эта операционная система весьма бурно развивалась в своей отрасли — обьединении компьютеров в единое целое. Понятие о кодовой странице в Unix имело несколько другое значение, но на этом сейчас останавливаться не стоит.
С развитием сетевых технологий возникла тенденция к обьединению не только компьютеров, расположенных в одном месте, в локальные сети, но и самих этих сетей в некое единое целое. Начала зарождаться Всемирная Сеть — Internet. И одной из первых возможностей обьединенной сети стала возможность обмена информацией посредством текстовых сообщений — электронная почта, e-mail.
Для работы с электронной почтой, ее передачи и приема, сортировки и разработки маршрута движения были созданы специальные системы — почтовые сервера. Сам по себе "почтовый сервер" — это программа, постоянно работающая на компьютере и выполняющая задачи по обработке почты, поступающей на компьютер, на котором она запушена, из Сети и отправляющая почту в Сеть. (Однако нередко для работы такой программы выделялся отдельный компьютер.) Чаще всего они работали под управлением операционной системы Unix.
Всемирная Сеть изначально зародилась и начала развиваться в Америке. Поэтому вся система почтовых серверов вначале была предназначена для работы с почтой англоязычных пользователей, пишущих также англоязычным адресатам. Так как использование в текстовых сообщениях, которые составляли тогда единственное содержимое электронной почты, символов псевдографики было отнюдь не обязательно (хватит и простого текста!), то программы, работающие с электронной почтой, как на компьютерах пользователей, так и на почтовых серверах, делались в расчете на первую половину кодовой страницы — на семибитную кодировку.
Ясно, что текстовые сообщения, содержащие символы с кодами, большими 127 и не могущие быть закодированы семью битами, нормально такими серверами обрабатываться не могли. Для того, чтобы такие письма все же как-нибудь проходили через семибитные почтовые серверы, символы сообщений принудительно приводились к семибитному виду — у них обнулялся первый бит, указывающий на половину их кодовой страницы. Например, символ «е» (русская буква е) переходил в «f», символ «ш» — в «y». Дальше шло уже обработанное таким образом письмо.
Если бы все почтовые сервера тогда были восьмибитные (то есть умеющие корректно работать с символами второй половины кодовой страницы), то пересылка через них русскоязычной почты не составляла бы проблем — лишь бы компьютеры отправителя и получателя поддерживали бы русскую кодовую страницу (или, в случае операционной системы Windows, и отправитель, и получатель имели бы шрифт с русскими символами). Ну и пусть в пути письмо не могло быть никем прочитано, у кого нет русской кодовой страницы (оно отобразилось бы на их компьютерах как мешанина символов) — даже лучше! Но обрезающие письма сервера не позволяли так делать.
Выходы были. Первый, самый тогда распространенный — писать письмо транслитом, latinskimi bukvami. Некрасиво и плохо читаемо, зато надежно — дойдет в исходном виде всегда. Но, поскольку все же не все почтовые сервера были семибитные, была создана специальная кодировка для электронной почты, которая отличалась тем, что на места, соответствующие кодам символов, большим 127, были поставлены русские символы, похожие по звучанию на английские буквы на местах, соответствующих кодам символов, меньших на 128. Иными словами, в этой новой кодировке коды 225, 226, 227, 228 соответствовали символам «а», «б», «ц», «д», которые при семибитном преобразовании перешли бы в коды 97, 98, 99, 100, соответствующие английским буквам «a», «b», «c», «d». Слово «привет», написанное в новой кодировке, пройдя через семибитный почтовый сервер, перешло бы в слово «PRIWET», что еще хоть как-то читаемо. Ну, а если письму бы повезло и на его пути не встретились бы семибитные сервера, то оно дошло бы в исходном виде.
Новая кодировка была названа KOI-8. Так как системы на основе Unix были в основном рассчитаны на работу с электронной почтой и международными сетями, то она стала стандартом для этой системы. Количество семибитных серверов стало понемногу сокращаться, сейчас их уже почти совсем не осталось в мире, а кодировка уже стала общепринятой, и программы для Unix предназначены для работы именно с ней.
KOI-8 использовалась не только Unix-системами. Так, любой пользователь персонального компьютера под управлением MS-DOS или Windows, имеющий выход к электронной почте, должен был иметь у себя программу для получения и отправки сообщений, умеющую работать с KOI-8. Выход к системе электронной почты был возможен и с компьютеров фирмы Apple — с Макинтошей, однако в операционных системах для этих компьютеров использовалась своя, оригинальная русская кодировка символов, отличающаяся от всех остальных. Для того, чтобы облегчить переписку между пользователями разных типов компьютеров и операционных систем, KOI-8 была принята как универсальная кодировка, и любая почтовая программа была обязана уметь читать и отправлять сообщения в этой кодировке.
Слишком умные серверы
Наличие пяти различных кодировок для русского языка создало определенные проблемы. Прежде всего, возникла необходимость в специальных программах-перекодировщиках, о которых речь пойдет ниже. Но самая большая проблема оказалась в российских почтовых серверах.
Казалось бы, а в чем она могла заключаться? Главное, чтобы серверы могли обрабатывать сообщения в восьмибитных кодировках, и тогда в какой бы кодировке сообщения не пересылались, они всегда могли бы быть прочитаны принимающей стороной с помощью программы, умеющей работать с этой кодировкой. Но, увы, не все оказалось таким простым… В некоторые почтовые серверы их создатели вложили возможность автоматической перекодировки поступающих сообщений — возможно, для некоей «стандартизации»: глупый пользователь, ничего не понимающий в компьютерах, написал и отправил письмо в кодировке Windows-1251, - так надо его письмо перевести в KOI-8, чтобы было, как у нормальных людей, никогда не использующих Windows! Хотя, может быть, у создателей перекодирующих серверов были и иные соображения.
Если на такой перекодирующий сервер поступит сообщение в кодировке Windows-1251, и он его воспримет именно как сообщение в этой кодировке, то письмо преспокойно будет перекодировано в KOI-8 и отправлено дальше. О том, в какой кодировке написано письмо, всегда указывается в его заголовке или тексте. Просмотреть текст сообщения именно в том виде, в каком сообщение передается почтовыми серверами (то есть со всей служебной информацией) можно в любой почтовой программе. Например, в Microsoft Outlook Express 5.0 это можно сделать, щелкнув правой кнопкой мыши на письме, выбрав из контекстного меню пункт «Свойства», а в появившемся окне — вкладку «Подробности». Тогда можно будет просмотреть заголовок сообщения. Нажав на кнопку "Исходное сообщение", вы увидите текст письма так, как он передается по Сети. Кодировка письма указывается в заголовке сообщения (рис. 13.7).
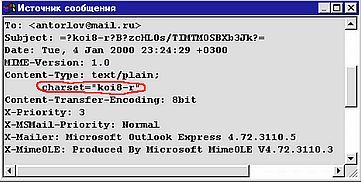 |
Рис. 13.7.
Русская версия Microsoft Outlook Express 5.0 по умолчанию для всех отправляемых сообщений ставит кодировку KOI-8 и сообщения отправляет именно в этой кодировке. Однако некоторые почтовые программы могут делать ошибки — письмо написано, например, в KOI-8, а программа пишет в заголовке письма, в служебной информации, что письмо имеет кодировку Windows-1251. Если такое письмо будет отправлено адресату, то оно сразу не сможет правильно отобразиться в его почтовой программе — на экране будет мешанина символов вроде той, что помещена в заголовке этой главы. Поскольку почти все почтовые программы позволяют просматривать одно и то же письмо в различных кодировках, то получатель письмо прочитать все же сможет, просто выбрав для него правильную кодировку.
Но если такое письмо — с несоответствующим содержанию заголовком — попадет на перекодирующий почтовый сервер, то ситуация резко осложнится. Посмотрев на заголовок письма, сервер решит, что, раз оно написано в Windows-1251, как там указано, то оно должно быть перекодировано в стандартную для Сети (по мнению сервера и его создателей) кодировку KOI-8. К письму будет применено преобразование Windows-1251 — KOI-8: будут заменены соответствующие коды символов. Но письмо-то уже изначально было в KOI-8! И что получается? Автор письма написал в нем "Добро пожаловать". В KOI-8 оно перекодировалось как "дНАПН ОНФЮКНБЮРЭ". А сервер эту фразу снова перекодировал по тем же законам, что и любая перекодировка из Windows-1251 в KOI-8. И получилось: "Дмюом нмтчймачпщ". Понять что-либо уже так просто стало невозможно.
Ну, а если на пути письма попалось несколько перекодирующих почтовых серверов, и оно было перекодировано не один раз, то дешифрация такого письма становится крайне сложной задачей.
Вложенные файлы
Изначально система электронной почты предназначалась для обмена исключительно текстовыми сообщениями и не могла пересылать файлы, приложенные к письмам, так как последние обычно являлись архивами и представляли собой двоичные данные, то есть не раскладывающиеся на удобовразумительную последовательность символов.
Безусловно, можно было принудительно разбить последовательность бит в файле на группы из восьми бит и попытаться перевести его в текст (эксперимент может проделать каждый, переименовав какой-либо исполняемый файл или архив в файл с расширением".txt" и загрузив его в Microsoft Word 97 или Microsoft Word 6.0), но в этом случае в таком тексте было бы большое количество символов с кодами меньше 33 и больше 127, из которых со вторыми могла бы возникнуть проблема обрезания старшего бита в семибитных почтовых серверах, описанная выше, а первые могли очень своеобразно отобразиться в почтовой программе. Кроме того, символы с кодами, большими 127, имели шанс подвергнуться перекодировке в российских почтовых серверах. Ясно, что после подобных преобразований вряд ли пересылаемая программа бы заработала, а архив открылся — их код стал бы практически невосстановимо испорченным.
Поэтому были разработаны специальные системы вложений двоичных файлов в почтовые сообщения, основанные на конвертации двоичных данных в набор символов с кодами от 33 до 127, могущий быть впоследствии подвергнутым обратному преобразованию в исходные двоичные данные. Систем такой конвертации было разработано несколько, самые употребительные из них — uuencode, base64, quoted-printable.
Почтовая программа, умеющая работать с вложениями, конвертировала перед отправкой письма вложенные файлы в одну из таких кодировочных систем, помещая перед вложением соответствующее указание на такую конвертацию, а при получении письма с вложениями просматривала текст письма и при нахождении вставки фрагмента, закодированного как, например, uuencode или base64 (что определялось по специальному указателю в тексте письма), превращала этот фрагмент в исходный двоичный файл. Сейчас все общеупотребительные почтовые программы умеют это делать.
Вот, к примеру, фрагмент письма с вложением, просматриваемый с помощью функции Microsoft Outlook Express "Свойства-Подробности-Исходное сообщение" (рис. 13.8).
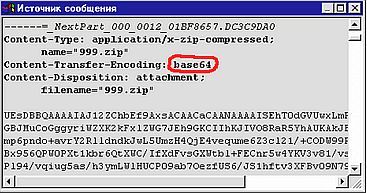 |
Рис. 13.8.
Все как на ладони. Указано, что приложено к письму — архив Zip с названием 999.zip, указан способ конвертации вложения — base64, а дальше идет набор символов первой половины кодовой таблицы, за который можно быть уверенным, что он пройдет через любые почтовые серверы неизмененным. Outlook Express при получении такого письма распознает наличие вставки base64, отобразит вложенный файл на панели вложений и позволит сохранить его на жесткий диск или прочитать, подвергнув обратному преобразованию из base64.
Если вложенный файл является текстовым (наиболее частый случай — HTML-вариант письма, который может быть составлен, к примеру, с помощью программы Outlook Express), то для него, помимо способа конвертации (обычно quoted-printable), указывается еще и кодировка исходного текстового файла для того, чтобы почтовая программа получателя, раскодировав его, могла его правильно отобразить (рис. 13.9).
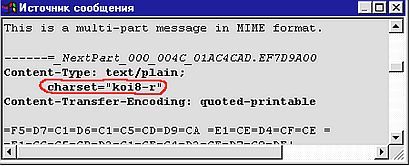 |
Рис. 13.9.
Иногда встречаются семибитные сервера, которые не "обрезают восьмой бит", а попросту обнуляют все символы с кодами, большими 127. В этом случае пришедшее письмо выглядит как набор вопросительных знаков, и никакая перекодировка не помогает — информация об исходных кодах символов оказывается полностью потерянной. В этом случае использование системы конвертации вложений для самого текста письма позволит ему проходить и по таким почтовым серверам.
Решение проблем
В связи с наличием пяти различных кодовых страниц для русского языка возникает две проблемы:
Для решения этих проблем есть много способов, реализуемых с помощью специальных программ или компонентов программных пакетов. Ниже будет рассказано о некоторых из них.
Да-да, не удивляйтесь — как ни странно, в этом редакторе есть средство открытия файлов в другой кодировке! Правда, поддерживается только возможность открытия и сохранения файлов в кодировке MS-DOS, но и это немаловажно — именно в этой кодировке распространяется большинство книг в "электронных библиотеках", огромное количество документов подготовлено в редакторах под MS-DOS и сохранено в текстовом формате в кодировке MS-DOS. Как же использовать это средство?
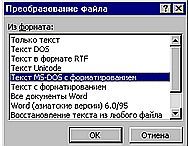 |
Для начала в меню Сервис-Параметры-Общие надо поставить флажок в графе "Подтверждать преобразование при открытии". После этого при открытии с помощью диалогового окна «Открыть» любых файлов с расширением, отличным от".doc", будет выдаваться диалоговое окно (см. слева), где можно будет выбрать нужный формат файла из предложенного списка.
Если вы открываете таким образом текст, представленный в кодировке MS-DOS, то лучше всего выбрать пункт "Текст DOS". Тогда при открытии файла его текст будет просто отображен на экране. Если файл, открытый таким образом, отредактировать и сохранить, то его формат сохранится, — он по-прежнему останется написанным в кодировке MS-DOS. Чтобы сохранить его в Windows-1251, надо воспользоваться пунктом меню "Файл-Сохранить как…" и указать там "Только текст" для сохранения в текстовом файле или другой формат для сохранения в нем.
При выборе в диалоговом окне выбора формата для открытия файла пункта "Текст MS-DOS с форматированием" Word предпримет попытку «отконвертировать» текст в формат Word. При наборе текста в редакторах под MS-DOS в качестве символа конца строки обычно используется символ конца абзаца (то есть клавиша "Enter"), а табуляция и выравнивание по центру или правому краю обозначаются пробелами. Применить к такому тексту методы форматирования (задание нужных полей и отступов, колонок, выравнивания по ширине) не представляется возможным, так как символы конца абзаца на концах строк будут мешать и не позволят тексту свободно перетекать из одной строки в другую, что требуется при подобном форматировании. Встроенный конвертор Word пытается исправить эту ошибку, но, увы, чаще всего делает это неудовлетворительно, и текст потом долго приходится править вручную.
В русской версии Microsoft Office 97 Professional есть специальный встроенный конвертер "Лексикон для DOS", его можно установить, выбрав соответствующий пункт при установке самого Office, но работа этого конвертера, хоть и несравненно лучше первого, все же оставляет желать лучшего.
Существует программа "Конвертор текста MS-DOS", специально предназначенная для обработки и оптимизации текста, набранного в MS-DOS. Разработка представляет собой макрокоманду для Microsoft Word 97 и Microsoft Word 2000 и запускается из Word. Она, кроме удаления лишних символов конца абзаца, также на основе количества пробелов перед первой буквой в строке устанавливает значение выравнивания (по ширине, по центру, по правому краю), заменяет несколько идущих подряд пробелов на один ("Лексикон" для MS-DOS пытается с помощью добавления лишних пробелов передать выравнивание текста по ширине), оптимизирует пробелы вокруг точек, запятых, других знаков препинания — ведь, в самом деле, пробел перед запятой выглядит несколько странно. Имеется возможность обработки сразу большого количества файлов с автоматическим их сохранением. Программа имеет множество настроек, могущих удовлетворить почти всех требовательных пользователей. "Конвертор текста MS-DOS" является частью пакета программ «ВерсткаТекстаКнижкой» и распространяется вместе с ним. Вы всегда можете загрузить этот пакет с адресов: http://antorlov.chat.ru и http://www.newtech.ru/~orlov.
К сожалению, работа с кодировками KOI-8, ISO-8859-5, Macintosh в среде Microsoft Word невозможна. Существуют макросы для перекодирования текста из KOI-8 в загруженном в Word тексте, но они работают медленно и поэтому пользоваться ими нецелесообразно.
В Microsoft Word 2000 и Microsoft WordXP при открытии документа в кодировке MS-DOS производится попытка автоматической его конвертации в читаемый вид, однако она не всегда срабатывает корректно.
Если под рукой нет ни Microsoft Office, ни каких-либо других программ для чтения текстов MS-DOS, то можно на крайний случай воспользоваться текстовым редактором WordPad, поставляющийся вместе с Windows9x. В меню этого редактора "Открытие файла" в качестве шаблона для имени файла надо указать пункт "Текстовые документы MS-DOS", и тогда открываемый текстовый файл будет отображен правильно.
С помощью вышеописанных средств — возможностей Word и WordPad — можно иногда выходить из положения, когда срочно надо напечатать или отредактировать файл, набранный в редакторах под MS-DOS, но при большом количестве таких файлов работа с ними станет весьма затруднительной. Однако в настоящее время имеется достаточно большое количество различных бесплатных программ, написанных русскими программистами специально для решения проблем совместимости различных кодировок. Одной из таких разработок является TextViewer Георгия Гуляева (рис. 13.10).
 |
Рис. 13.10.
TextViewer открывает текстовые файлы и файлы в формате Rtf. Слева вверху на панели инструментов программы находятся шесть кнопок — пять из них позволяют просмотреть открытый документ в соответствующей кодировке (Dos-866, Windows-1251, KOI-8, Macintosh, Iso-8859-5), а шестая — просмотреть текстовое содержимое файла в формате Rtf, если таковой будет загружен в TextViewer. Открытый файл можно сохранить в нужной кодировке, выбрав соответствующую опцию в окне "Файл-Сохранить как…". Имеется возможность произвести печать файла, использовать функцию предварительного просмотра перед печатью, поиск в тексте и замену фрагмента. Можно выбрать шрифт для отображения текста, с помощью удобного диалогового окна связать программу TextViewer с различными типами текстовых файлов.
В целом можно сказать, что разработка Георгия Гуляева — превосходная замена стандартному «Блокноту». Возможность работы с различными кодировками, открытие файлов любого размера, возможность замены — все это дает TextViewer'у неоспоримые преимущества перед Notepad'ом. Однако на компьютерах, не оснащенных процессором Pentium, TextViewer весьма медленно запускается, в связи с чем использование его как стандартного редактора текстовых файлов, например, на 486-м процессоре будет затруднительно.
Загрузить TextViewer можно с сайта Георгия Гуляева "http://www.freespeech.org/georgy" или с сервера бесплатных программ "http://www.freeware.ru".
Aditor — мощный текстовый редактор, отличающийся наличием множества разнообразных функций, в числе которых есть и возможность чтения и записи файлов в различных кодировках.
Чрезвычайно важной и редкой является возможность работать с текстом, написанным на Translit'е — то есть latinskimi bukvami. Иногда только такое письмо имеет шанс быть правильно прочитанным адресатом (например, когда у адресата вообще нет русифицированных программ на компьютере и работа с русскими кодовыми страницами невозможна, а также в случае, когда на пути письма стоит семибитный почтовый сервер). Aditor позволяет легко подготовить такое письмо и при необходимости прочитать текст на Translit'е.
Загрузить Aditor можно с адреса "http://perecod.chat.ru/aditor.rar" или с сервера бесплатных программ "http://www.freeware.ru".
Программа "Exclude Symbols" Вардугина Александра из Кемерова является многофункциональным пакетным обработчиком текстовых файлов. Как видно из рисунка 13.11, программа поддерживает четыре кодировки — Windows-1251, KOI-8, Dos866 и Iso-8859-5, позволяя переводить текстовые файлы из одной кодировки в другую. Допустима обработка до пятнадцати файлов за один раз: файлы обрабатываются последовательно. В программе есть также ряд весьма интересных функций, например, превращения всех символов в файле в заглавные или, наоборот, в строчные, удаления пустых строк из текста, замены групп пробелов табуляцией, замены символов в обрабатываемых файлах.
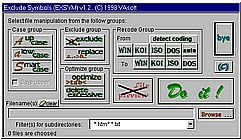 |
Рис. 13.11.
Обращает на себя внимание интересная возможность автоматического определения кодировки документа. Делается это по довольно очевидному алгоритму. Вот пример. В русском языке есть союзы «и» и «в», но нет ни союзов «Ё» и "ў" (символы кодовой страницы Windows-1251, имеющие такие же коды символов, как и символы «и» и «в» в кодовой странице Dos866), ни союзов «Й» и «Ч» (символы кодовой страницы Windows-1251, имеющие такие же коды символов, как и символы «и» и «в» в кодовой странице KOI-8). Поэтому ясно, что текст, открытый как имеющий кодировку Windows-1251, в котором встречаются одиноко стоящие символы «и» и «в», скорее всего, и принадлежит кодовой странице Windows-1251, если же в нем встречаются одиноко стоящие символы «Ё» и "ў", то это, скорее всего, текст в кодировке MS-DOS, а если в этом тексте есть одинокие символы «Й» и «Ч», то, наверное, текст написан в кодировке KOI-8. На подобных принципах основан и способ автоматического определения кодировки документа в программе "Exclude Symbols". Поэтому можно, указав в качестве обьекта для перекодирования группу файлов, не особенно беспокоиться о кодировке каждого из них — достаточно просто указать ту кодировку, которую нужно получить на выходе, а в качестве исходной поставить значение «auto». Программа сама определит для каждого обрабатываемого файла его исходную кодовую страницу, решит, нужна ли ему конвертация в другую кодировку и при необходимости выполнит такую конвертацию.
Обращает на себя внимание оригинальный и удобный нестандартный интерфейс программы. Загрузить "Exclude Symbols" можно с адреса http://perecod.chat.ru/exsym.rar.
Программа «Штирлиц», помимо возможности чтения текстов в различных кодировках, в том числе и в Unicode, имеет очень важную и нужную функцию — функцию расшифровки неоднократно перекодированных почтовых сообщений.
Как уже писалось выше, электронное письмо, пройдя через несколько перекодирующих серверов, может стать совершенно нечитаемым. Для его расшифровки необходимо найти ту последовательность перекодировок, которым оно подверглось, и применить к письму обратное преобразование. Именно это делает «Штирлиц», созданный Всеволодом Лукьяниным. Если в него загрузить (например, перенеся с помощью буфера обмена или открыв сохраненный на диске текстовый файл) нечитаемый текст, полученный в качестве письма, то программа после вызова соответствующей функции начнет перебор возможных вариантов перекодирования, пытаясь найти ту последовательность перекодировок, которой подверглось письмо, и применить к нему обратные перекодировки. Пользователю показывается наилучший, по мнению программы, вариант раскодированного письма, — «Штирлиц» анализирует раскодированный текст и, если находит там общеупотребительные слова русского языка, то считает этот вариант раскодировки наилучшим.
Программа отличается большим набором режимов работы и функций. Так, можно подбирать схему перекодировок вручную (если есть для этого какие-нибудь предположения), задавать глубину анализа (то есть сколько раз подряд это письмо могло быть неправильно перекодировано), раскодировать текст, разные фрагменты которого имеют разную кодировку, читать тексты, написанные в Unicode-кодировке, читать тексты, написанные на Translit'е. Имеется подробное руководство пользователя и очень удобная функция деинсталляции, которая может служить примером написания таких программ. «Штирлиц» способна вытаскивать из текста письма фрагменты, закодированные в uuencode, base64 и других подобных системах передачи вложенных файлов, если почтовая программа получателя не распознала их. Для этого в «Штирлице» есть специальная функция. Кроме того, при наличии какого-либо текста в закодированном в uuencode, base64 или другом подобном формате фрагменте письма программа сможет его «вытащить» и показать пользователю.
В программе есть возможность пакетного перекодирования файлов в нужную кодировку, при этом исходная кодировка каждого файла определяется автоматически и в соответствии с ней выбирается нужный алгоритм перекодирования.
Вместе с тем программа «Штирлиц» не лишена и некоторых недостатков. Так, к сожалению, очень некорректно выполняется перекодировка в кодовую таблицу Dos866 и обратно. Несмотря на то, что при этом письмо остается в какой-то степени читаемым, выглядит оно очень непрезентабельно. Так что использование «Штирлица» в качестве программы для чтения файлов в разных кодировках может сопровождаться некоторыми затруднениями. Поэтому лучшее применение, несомненно, превосходного творения Всеволода Лукьянина — «спасение» неправильно перекодированных почтовых сообщений.
Загрузить «Штирлиц» можно с адреса http://perecod.chat.ru/shtirlz.rar.
Эта программа Покровского А.В. - простое, но очень хорошо работающее средство для раскодирования писем, прошедших через несколько перекодирующих почтовых серверов. Она просто анализирует текст и преобразует его в читаемый вид. Несмотря на отсутствие сложных настроек и дополнительных возможностей, функцию свою «Декодер» (рис. 13.12) выполняет просто превосходно.
 |
Рис. 13.12.
Для раскодирования текста надо просто вставить его в окно программы и нажать кнопку «Расшифровать». «Декодер» имеет просто превосходный интерфейс, который среди всех программ, описанный в этой главе, без сомнения, заслуживает наибольших похвал. Видно, что автор программы подумал об эргономике, удобстве пользователя, легкости и простоте работы. Это, к сожалению, редкая ситуация, и даже у лучших программ других авторов интерфейс и средства управления программой оставляют желать лучшего. Всем потенциальным авторам программ настоятельно рекомендуется ознакомиться с творением А.Покровского и, по возможности, последовать его примеру в области разработки пользовательского интерфейса. Без сомнения, эта маленькая, но мощная и очень удобная программа достойна того, чтобы занять почетное место на жестком диске каждого пользователя, работающего с электронной почтой и хотя бы изредка сталкивающегося с проблемой восстановления неправильно перекодированных почтовых сообщений.
Загрузить программу можно с сайта разработчика www.postman.ru/~a12/decoder.
Программа TСode Алекса Бойко (рис. 13.13) — пожалуй, самый мощный инструмент для восстановления многократно перекодированных файлов. Ей подвластна практически любая комбинация перекодирующих серверов. Кроме того, она умеет работать с системами конвертации вложенных файлов base64 и quoted-printable. TCode по своему действию похожа на предыдущую описанную программу, только позволяет проводить также и ручную перекодировку.
 |
Рис. 13.13.
Кроме того, TCode позволяет проводить и обычную конвертацию текста из одной кодировки в другую, что иногда может пригодиться при подготовке web-страниц. Надо только в меню в окне программы отказаться от использования автоопределения кодировки.
При испытаниях TCode справилась даже с такой нетривиальной задачей, как раскодирование письма, пять раз неправильно перекодированного (для этого письмо сохранялось как KOI-8, а открывалось как Windows-1251 в виде мешанины символов, и опять сохранялось как ISO-8859-5, и так пять раз). На расшифровку такого письма размером в полкилобайта с помощью TCode ушло около 10 минут на Pentium-166, причем результат был вполне читаем, хотя и не совсем полностью правилен.
Загрузить TCode можно с адреса http://perecod.chat.ru/tcode.rar или с сайта автора http://alexboiko.da.ru. Не забудьте отказаться в меню Settings от автоматического перекодирования буфера обмена, а то во время работы TCode вы не сможете с ним работать в других программах.
* * *
Что касается личного предпочтения автора, то у меня в качестве заменителя Notepad'а стоит TextViewer Георгия Гуляева, для восстановления почтовых сообщений (которое благодаря усилиям разработчиков программного обеспечения требуется все реже и реже) используется программа А.Покровского (одно удовольствие с ней работать — уж больно хорошо спроектирована и написана), а для массовой перекодировки файлов, если такая необходимость возникает, я использую Exclude Symbols. Для конвертации текста, набранного в редакторах для MS-DOS, в формат, допускающий свободное его редактирование (то есть изменение отступов, выравнивания) я применяю "Конвертор текста MS-DOS", поскольку он отличается множеством полезных настроек и позволяет обрабатывать документы в пакетном режиме. Если же возникает необходимость написать или расшифровать текст на Translit'е, то дается работа Aditor'у.
Если же "Декодер почты" не справляется со своей задачей (а такое случается крайне редко), то приходит черед TCode, перед которой не устоит ни одно письмо, если оно, конечно, в принципе может быть прочитано.
Будем надеяться, что в будущем проблема различных кодировок как-нибудь будет решена. Может быть, наилучшим решением было бы принятие всеми какой-либо кодировки как стандарта. Но это уже зависит от воли производителей программного обеспечения.
Полезные советы
· Если вас не устраивает максимально допустимое в Microsoft Paint увеличение рисунка, равное восьми крат, то вы можете использовать скрытую возможность этого графического редактора. Нажмите кнопку с изображением линзы, а затем кликните левой кнопкой мыши на нижней границе поля, в котором показываются возможные степени увеличения. Рисунок будет увеличен в десять раз.
· Чтобы при загрузке Windows9x при необходимости проверки диска срабатывала альтернативная программа проверки диска, нужно в подпапку Command той папки, куда установлена Windows, поместить ее исполняемый файл, переименовав его в "scandisk.alt".
· Для того, чтобы поместить в буфер обмена изображение экрана, воспользуйтесь клавишей PrintScreen. Комбинация клавиш Alt+PrintScreen поместит в буфер обмена изображение активного окна.
· Если компьютер будет эксплуатироваться в условиях повышенной вибрации или на одном столе с ним располагается матричный принтер, то положите под системный блок поролоновый коврик толщиной 2–3 см. Позаботьтесь о своих жестких дисках — вибрация для них вредна.
· Если вам нужно перенести с помощью дискет с одного компьютера на другой файл, который по размеру больше емкости дискеты, то не ищите специальных программ для «нарезки» файлов. Возьмите архиватор Rar или WinRar. В нем есть превосходная функция "создания многотомных архивов". Задайте в диалоговом окне установки параметров архива размер тома, равный размеру дискеты, а потом перепишите на дискеты созданные тома — на каждую по одному. Если на том компьютере, куда необходимо перенести файл, не установлен Rar, то создайте самораскрывающийся (SFX) — архив, — в этом случае архив будет представлять из себя программу, которая сама извлечет из себя свое содержимое. Обязательно отметьте пункт добавления "информации для восстановления" при архивации — тогда небольшие повреждения архива не скажутся на его содержимом, а лучше копируйте каждый том архива сразу на две отдельные дискеты — в этом случае вероятность одновременного неустранимого повреждения обоих томов будет минимальной.
| © 2024 Библиотека RealLib.org (support [a t] reallib.org) |