"Домашний компьютер № 9 (123) 2006" - читать интересную книгу автора (Домашний_компьютер)
Утонченное чтиво Автор: Евгений Яворских.
Жизненное наблюдение: едва освоив назначение кнопок системного блока, некоторые сразу же причисляют себя к клану IT-профессионалов — теперь им обеспечено внимание и почет со стороны тех, кто так и не научился правильно выключать компьютер. Самое забавное, что амбиции этих «профи» чрезвычайно высоки: если системный блок — то самый навороченный, если мышка — то непременно профессиональная
Неизбывная вера в некие магические функции Pro-версий программного обеспечения витает в головах и более толковых граждан. В самом деле, чем же отличаются профессиональные версии программ от домашних? Может быть, Pro работают лучше, нежели их простые собратья? Есть ли смысл расходовать дисковое пространство на более «тяжелые» вариации софта или достаточно обычных версий? Не следует забывать и о материальной стороне вопроса: неискушенный пользователь рискует истратить гораздо большую сумму за Pro-инкарнацию программы, нежели за обычную (или Home).
Попробуем разобраться с программными «профессионалами» на примере линейки продуктов для распознавания текста от компании ABBYY — семейство FineReader (или «Утонченный Чтец» в вольном переводе). Полагаю, четырех приложений, различающихся функциональными возможностями и, разумеется, ценой, будет вполне достаточно. Однако для более корректного сравнения возможностей этих программ следует уяснить основные принципы систем распознавания текста.
Представьте ситуацию, когда вам требуется ввести в компьютер солидный объем информации: это могут быть книжные и альбомные страницы, офисные документы, газеты и прочее. Согласитесь, перспектива столь рутинного труда вряд ли способна обрадовать, поэтому и были придуманы системы распознавания или OCR-системы (Optical Character Recognition). Все, что вам понадобится — это сканер, программа распознавания и, конечно же, исходные «бумажные» документы (толковые OCR-системы умеют распознавать текст в графических и PDF-файлах).
Механизм работы с такой системой чрезвычайно прост: вы загружаете документ в сканер, нажимаете определенную кнопку в окне программы, проверяете полученный результат, после чего даете команду сохранить распознанную информацию в один из поддерживаемых форматов (Word, Excel, HTML, RTF, PDF, TXT). Наиболее трудоемкая операция — это проверка результата распознавания и воссоздание оформления исходного документа: количество ошибок, допущенных при этом, в идеале должно быть единичным, а качество передачи оформления исходного документа должно максимально соответствовать «исходнику».
Немаловажную роль играют языки распознавания, встроенная поддержка проверки орфографии
Качество распознавания во многом зависит от параметров сканируемого изображения. Качество изображения регулируется установкой основных параметров сканирования: типа изображения, разрешения и яркости. Оптимальным типом в данном случае считается «Серый (256 градаций)», при этом будет осуществлен автоматический подбор яркости. Черно-белый тип обеспечивает более высокую скорость сканирования, но при этом будет утрачена часть информации о буквах, что может привести к ухудшению качества распознавания на документах среднего и низкого качества печати.
Если вам нужно, чтобы цветные элементы сканируемого документа (иллюстрации, цвет букв и фона) были переданы в FineReader точно, необходимо выбрать цветной тип изображения. Разрешение рекомендуется не более 300 dpi для обычных текстов (размер шрифта 10 и более пунктов) и 400—600 dpi для текстов, набранных мелким шрифтом (9 и менее пунктов). Для яркости в большинстве случаев подходит среднее значение — 50%.
Самый простой продукт распознавания (65 Мбайт) вы не сможете купить отдельно — он поставляется в комплекте со сканерами и многофункциональными устройствами. Ряд пользователей относятся к такому «сопутствующему» софту с легким презрением, полагая «Спринт» недостойным их внимания. Но возможно, на первых порах «Спринт» вполне устроит вас, поскольку удобен и прост в использовании, а распознавание документа происходит с помощью одной кнопки Scan amp;Read.
Предлагается 13 языков установки, в том числе и русский. Учтите, выбирая язык, вы тем самым определяете локализацию интерфейса: в дальнейшем этот параметр изменить невозможно. По умолчанию будут установлены значок ABBYY FineReader в панели инструментов MS Word, а также огромное число языков распознавания, сгруппированных в четыре категории: «Основные» (наиболее употребимые языки), «Дополнительные» (сюда попали, например, албанский, белорусский, фиджи и гагаузский), «Формальные» (языки программирования и простые химические формулы) и «Искусственные» (эсперанто, интерлингва и другие). Нет смысла вводить все языки распознавания, в особенности, если вы не работаете с документами на языке Чаморо или Гуарани — экономия дискового пространства
Интерфейс программы являет образец аскетизма: две активные кнопки плюс рекламная (рис. 1).
 |
Что сделает пользователь, начинающий знакомство с программой? Очевидно, в силу природного любопытства отправит под крышку сканера текстовый документ и нажмет кнопку «Сканировать». Точно так же поступим и мы, используя в качестве «подопытного кролика» страницу с русским текстом. Однако, каждый сканер имеет свою фирменную утилиту
Для предварительного просмотра сканируемого документа в утилите моего сканера используется кнопка Preview: после недолгой калибровки девайса в окне появляется исходный документ. Еще раз повторю: нет абсолютно одинаковых интерфейсов, и вам придется самостоятельно отыскать параметры, регулирующие разрешение сканирования и тип документа. В данном случае этим «ведают» опции Output Resolution и Color Mode, где и были заданы оптимальные параметры сканирования. В рассматриваемом примере нет нужды сканировать весь текстовый документ, содержащий поля большого размера, — кроме увеличения времени сканирования мы ничего не получим. При помощи кнопки обрезки выделим нужную область и запустим процесс (кнопка Scan).
По окончании сканирования страница документа отобразится в левой части окна FineReader 6.0 Sprint (рис. 2)
 |
— обратите внимание на слово «Изображение»: действительно, в данный момент наша исходная «бумага» представлена в графической форме, поскольку сканер не способен переводить результат своей работы в другой формат. Этим и будет заниматься программа распознавания. Теперь вспомним о языках распознавания: наш текст написан по-русски, следовательно, выбрать нужно именно русский в меню «Язык». Если будет выбран «не родной» язык, то результат распознавания не сможет расшифровать ни одна разведка мира. Теперь нажмем кнопку «Распознать» и спустя несколько секунд получим текст в правой части программного окна (рис. 3).
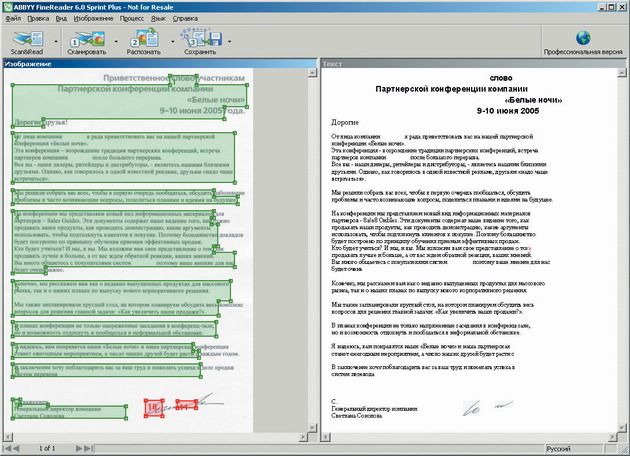 |
Увы, результат не радует — софтина выделила текстовые блоки зеленым цветом, что называется, «от фонаря», притом что текст исходного документа был напечатан очень качественно. В результате такой «вольности» распознался не весь текст. Интересный нюанс: автограф на «исходнике» был распознан как графический блок, но и здесь все очень плохо — два отдельных блока на несколько рукописных букв. В таких случаях можно исправить положение дел, если растянуть границы блоков, потянув мышью за узловые точки. Не так уж это и трудно, но есть и более простой способ: меню Процесс · Анализ макета страницы.
Замечательно, теперь выделен весь текст без малейших потерь, но ситуация с автографом не улучшилась (рис. 4)
 |
— что же, без ручной корректировки границ блоков нам не обойтись: потянув за угол зеленого блока на автографе, сдвинем зеленую границу вправо. Аналогичную операцию проделаем и с красными блоками, растянув один из них на всю площадь рукописного текста (рис. 5).
 |
Если программа ошибется и неверно определит тип блока (что бывает крайне редко), можно исправить положение посредством группы команд «Тип блока» в меню «Изображение»: при необходимости вы без труда измените текстовый блок на графический или табличный.
Повторно нажимаем на кнопку «Распознать», и, казалось бы, можно праздновать победу, ан нет. Проявился «глюк»: в тексте имеется словосочетание Sales Guide, и оно превратилось в «8а!е8 СиЫез». Причина станет понятной, если вы загляните в меню «Язык». В нашем случае текст — двуязычный, то есть кроме русского в нем встречаются несколько английских слов, а «Спринт» не умеет распознавать такие конструкции. Впрочем, в конкретном документе неверно распознанные символы несложно исправить вручную, но для этого потребуется сохранить результат в какой-либо удобоваримый формат: кнопка «Сохранить».
«Мастер сохранения результатов» предложит несколько вариантов готового документа (рис. 6)
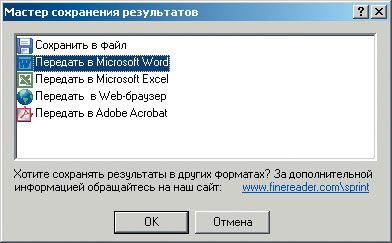 |
— вам достаточно выделить нужный формат и нажать ОК. Впрочем, можно обойтись и без услуг г-на «Мастера», если открыть выпадающее субменю кнопки «Сохранить». При конвертации в формат MS Word программа полностью сохранит как форматирование текста, так и размер и тип шрифта.
Обратите внимание на опцию «Передать в Adobe Acrobat»: у данной версии FineReader нет встроенного инструмента конвертации распознанного текста в PDF-формат, и она надеется на помощь стороннего продукта. Посмотрим, как поведут себя по отношению к PDF более продвинутые версии. Опция «Передать в веб-браузер» подразумевает создание веб-страницы. Для активации этой функции потребуется бесплатно зарегистрироваться на сайте разработчика: меню Справка · Активация экспорта в HTML
Вся линейка FineReader обучена распознавать не только отсканированный текст, но и графические изображения, содержащие буквы и цифры (поддерживаются форматы BMP, TIFF, PNG, DCX и PCX). Сергей Костенок заранее усложнил задачу, предложив «скормить» программе обложку одного из продуктов ABBYY
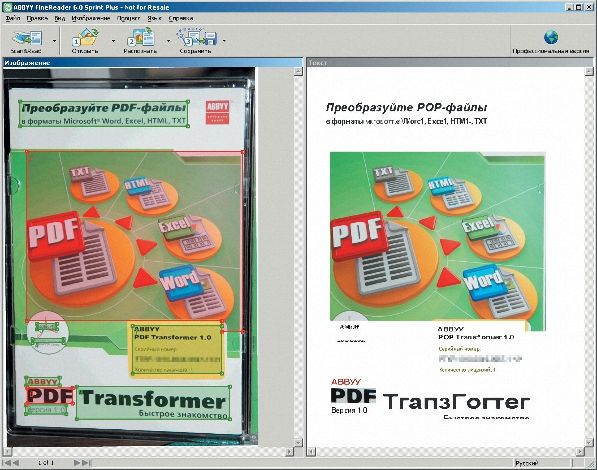 |
Неизвестно почему программа отказалась распознавать и логотип своей компании, а его, по логике, можно смело рассмаривать как графический блок. Ну да ладно: не зря в программном окне красуется здоровенная кнопка «Профессиональная версия». Похоже, снобизм части пользователей по отношению к «урезанным» версиям вполне оправдан?.. Давайте разбираться.
Российская разработка CuneiForm 2000 компании Cognitive Technologies (16 Мбайт, $129) призвана выполнять те же задачи, что и FineReader. Демо-версия CuneiForm 2000 рассчитана на 100 запусков или на использование в течение 30 дней и позволяет распознавать тексты на русском, английском, русско-английском, немецком и французском языках (в нее не входят 15 дополнительных языковых библиотек). На сайте разработчиков предлагаются два варианта программы: CuneiForm 2000 R2 с русским интерфейсом и CuneiForm 2000 Professional (английский интерфейс). В списке поддерживаемых операционных систем нет Windows 2000/XP. При установке CuneiForm 2000 R2 в среде WinXP приложение выдало ошибку и тихонько испустило дух. Правда, при установке в раздел FAT32 (Windows 98SE) все прошло благополучно. Оказалось, что сей продукт не работает в среде Windows 2000/XP (что неудивительно, ведь число 2000 в названии означает год появления продукта). Комментарии излишни…
Readiris Pro 7 — профессиональная программа. По словам производителей (20 Мбайт, $130), для данной OCR характерна высочайшая точность преобразования обычных печатных документов (письма, факсы, журнальные статьи, газетные вырезки) в объекты, доступные для редактирования (включая файлы PDF). Работает со всеми версиями Windows. Поддерживаются 92 языка, включая русский.
OmniPage 11 ($600), продукт компании ScanSoft. Разработчики утверждают, что их программа практически со 100% точностью распознает печатные документы, восстанавливая их форматирование, включая столбцы, таблицы, переносы, заголовки, названия глав, подписи, номера страниц, сноски, параграфы, нумерованные списки, красные строки, графики и картинки. Есть возможность сохранения в формат Microsoft Office, PDF и в 20 других форматов, распознавания из файлов PDF и редактирования в формате PDF.
Судя по размеру дистрибутива и стоимости продукта — 115 Мбайт и 1100 рублей — есть все основания надеяться на более качественную работу. Параметры установки те же, что и в ABBYY FineReader 6.0 Sprint, за исключением лишь двух языков установки (и, следовательно, интерфейса) — русского и английского. Не забывайте о колоссальном числе языков распознавания и в меню отметьте лишь необходимые, отбросив заведомую экзотику.
Окно домашней версии почти ничем не отличается, и, разумеется, кнопка «Профессиональная версия» никуда не исчезла
 |
Так в чем же разница? Ответ получим после сканирования «бумажного» документа (параметры сканирования ничем не отличаются от «спринтерских»). Результат гораздо лучше: текст полностью окружен зеленой границей блока, вот, разве что, с рукописной частью документа снова вышла накладка (рис. 9).
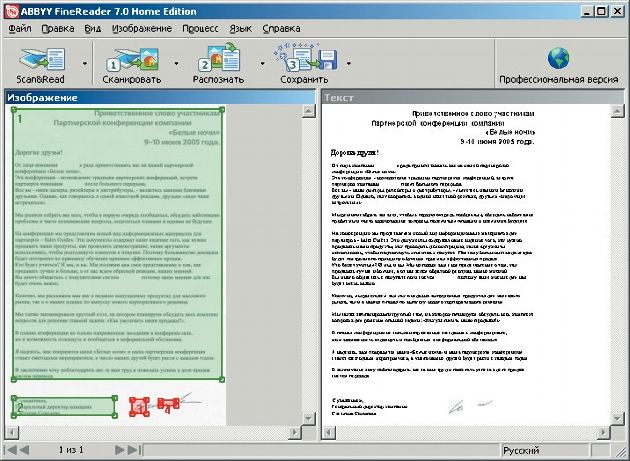 |
Но мы уже знаем, как исправить такое недоразумение.
По умолчанию предлагается русский язык распознавания, но, как вы помните, при сканировании документа, содержащего смесь латиницы и кириллицы, ничего хорошего не выйдет. Однако цена продукта себя должна оправдать: зайдите в меню Язык · Выбор нескольких языков и в открывшемся окне «Язык распознаваемого текста» поставьте флаг в переключателе «Русско-Английский» (рис. 10).
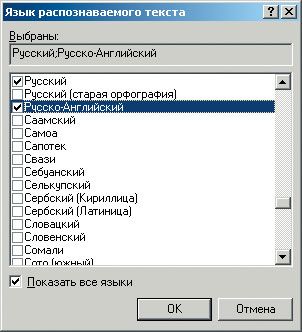 |
Теперь смело нажимайте кнопку «Распознать», радуйтесь абсолютно корректному результату, после чего сохраняйте сканированный документ в удобный для вас формат.
Точно так же, как и в ABBYY FineReader 6.0 Sprint, вам придется активировать опцию экспорта распознанного текста в HTML-формат, а для конвертации в PDF использовать «великий и ужасный» Adobe Acrobat — встроенный PDF-инструментарий отсутствует и в домашней версии. Лучше программа справилась и с распознаванием сложного графического файла с обложкой
С точки зрения функциональности Home-версия отличается от «Спринта» лишь одним: функцией выбора комбинации английского и русского языков распознавания. Безусловно, для части пользователей такая возможность более чем актуальна. Кроме того, даже наш небольшой тест показывает, что алгоритмы работы программ так же отличаются: так, лучше работает автоматическое выделение блоков, что уменьшает необходимость ручной подгонки. Осталось узнать, чем же столь хороша профессиональная версия, столь рекламируемая разработчиком. «Вскрытие» покажет.
Уж здесь-то все должно быть замечательно. А как же иначе? Аккурат — 383 Мбайта дистрибутива и цена 3700 рублей. Впрочем, можно загрузить испытательную версию (40,5 Мбайт), лишенную дикого количества языков распознавания, их при необходимости без труда можно загрузить с сайта компании. Мы же займемся установкой «коробочной» версии программы.
Что вы скажете о девятнадцати языках установки продукта? Согласен, мало кому из русскоязычных пользователей понадобятся эстонский или турецкий языки инсталляции. Зато следующий шаг оценят многие: меню выборочной установки предлагает несколько языковых вариаций программного интерфейса (рис. 11).
 |
Кроме того, по вашему желанию будут установлены «Руководство пользователя» в формате PDF, обучающие примеры и утилита ABBYY Screenshot Reader, способная распознавать текст не просто со скриншотов, являющихся графическими файлами (два предыдущих приложения умели «читать» графику), а непосредственно с экрана компьютера. Заманчиво.
Настоящий профессионализм не терпит суеты и спешки: установка FineReader 8.0 Professional Edition длится гораздо дольше своих «младших» собратьев — около пяти минут. При первом запуске софтины вам предложат онлайн-активацию продукта, занимающую несколько секунд времени, после чего, наконец-то, откроется главное окно (рис. 12).
 |
Поначалу разбирает смех: профессиональная версия настойчиво предлагает курс обучения на демо-примерах вкупе с услугами «Мастера Scan amp;Read» (рис. 13).
 |
Затем понимаешь, что данная версия подразумевает не только профессионализм пользователя, а скорее профессиональный подход к освоению программы, что существенно отличается от рассмотренных выше аналогов. Что касается по-настоящему толковых пользователей, так они не станут издеваться над приглашением «Мастера», а снимут флаг в чекбоксе «Показывать диалог при запуске ABBYY FineReader» и начнут работать.
На мой взгляд, профессионализм приложения — это и максимальная простота работы: обратите внимание на выпадающий список языков распознавания, где изначально предлагается «русско-английский коктейль». Казалось бы, мелочь, а экономия трудозатрат налицо. Та же картина и в выпадающем меню кнопки Scan amp; Read (рис. 14):
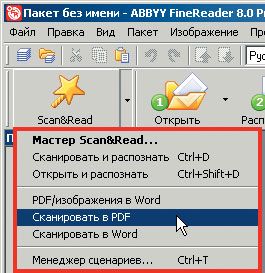 |
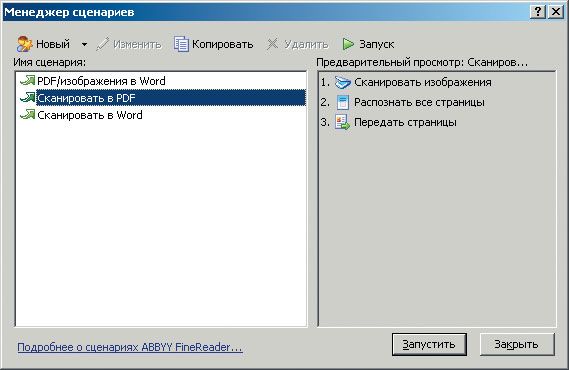
профессионал ценит свое время и не станет бездумно щелкать по кнопкам, он знает, что хочет от программы — например, «Сканировать в PDF». Это вам не услужливый «Мастер», а набор из трех программных сценариев, то бишь нескольких последовательных шагов, каждый из которых соответствует этапу обработки документа (рис. 15).
 |
И здесь экономия времени — переход от одного шага сценария к другому происходит автоматически.
Не нравятся встроенные сценарии? Сделайте свой, «заточенный» под определенный документ или ваше настроение в данное время суток: меню Сервис · Менеджер сценариев (Ctrl+T). Причем для собственных сценариев можно добавить и малую толику ручной работы, например, правку отсканированной страницы или создание блоков.
FineReader 8.0 Professional Edition умеет сохранять распознанную информацию в формате PDF. Для вывода диалога сохранения результатов не мудрствуйте, а нажмите комбинацию клавиш Ctrl+S и выберите нужный формат, включая PDF.
В отличие от программ, рассмотренных выше, профессиональная версия имеет функцию проверки текста (кнопка «Проверить»). Кроме «очепяток» будут отслеживаться символы, в правильности распознавания которых FineReader не уверен. Программа известит о «неуверенно распознанном символе» (рис. 16)
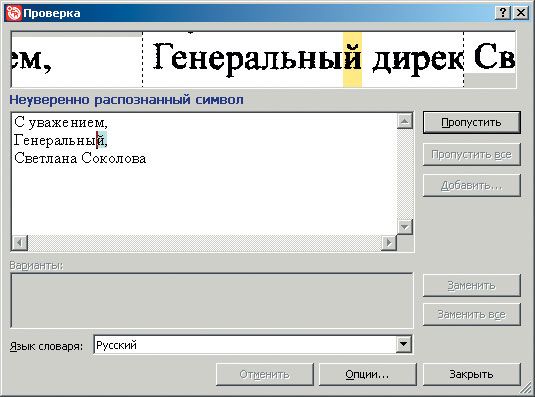 |
и будет терпеливо ожидать вашего решения — все точно так же, как и в аналогичном инструменте MS Word. Тексты хорошего и среднего качества, а также шрифты обычного начертания читаются без проблем, а для текстов, в которых используются декоративные шрифты или встречаются специальные символы (например математические), предусмотрен режим «Распознавание с обучением»: в меню Сервис · Опции перейдите на вкладку «Распознать» и поставьте флаг в переключателе «Распознавание с обучением» (рис. 17).
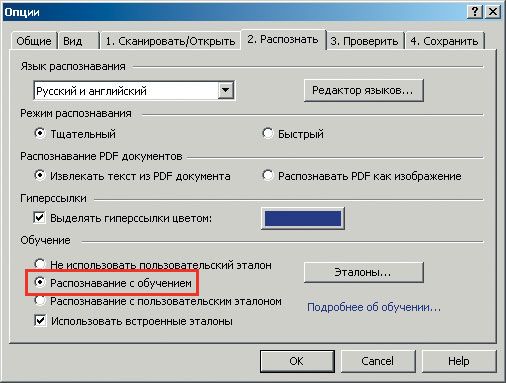 |
Обучение проводится при распознавании одной-двух страниц текста в специальном режиме, в результате создается эталон букв, встречающихся в тексте. Такой эталон в дальнейшем будет нужен при распознавании основного объема текста. Полагаю, теперь нет сомнений в профессионализме и утонченности программы. Возможно, вам покажется, что я пропустил описание опций в «Спринте» и Home-версии, но это не так. Дело в том, что никаких дополнительных опций в этих двух приложениях не существует.
Еще один довод в пользу совершенной работы FineReader 8.0 Professional кому-то покажется недостойным внимания, но, тем не менее, советую подробнее ознакомиться с кнопками инструментальной панели «Изображение» (рис. 18)
 |
или одноименным пунктом меню, позволяющими не только обрезать или поворачивать изображения, но и устранять искажения строк (если вы не включили данную опцию на вкладке «Сканировать/Открыть»).
Что касается качества распознавания текстовых документов, то, как и в случае с домашней версией, недостатки отсутствовали — по-моему, это лучшая характеристика. Точно то же можно сказать и о распознавании графического файла, упоминавшемся выше. Профессионал — он и в Африке профессионал.
Безусловно, FineReader 8.0 Professional в полной мере оправдывает свое «профессиональное» назначение. Но есть ли смысл домашнему пользователю переплачивать почти 100 долларов по сравнению с Home-версией, если распознавание русско-английской текстовой «смеси» заложено в оба продукта? Согласен, использование Professional в качестве инструмента для создания PDF-файлов представляется весьма выгодным, если вспомнить заоблачную стоимость Adobe Acrobat. Но мы уже рассказывали о полностью бесплатных продуктах для создания PDF-документов (см. ДК 7_2006), а потому будем считать встроенный PDF-инструментарий FineReader 8.0 Professional неактуальным в домашних условиях.
Не уверен, что и режим «Распознавание с обучением» будет востребован пользователем, эпизодически сканирующим обычный печатный текст с иллюстрациями. Что касается встроенной проверки орфографии, то при переводе сканированного документа в среду MS Word вы без труда сделаете «работу над ошибками» средствами текстового процессора. Впрочем, выбор за вами: либо малая толика ручной работы по корректировке границ блоков, либо профессионализм «утонченного чтеца».
Если вы думаете, что системный администратор станет бегать от компьютера к компьютеру с программным дистрибутивом, то ошибаетесь. Для облегчения труда многострадального админа давно существует так называемая «сетевая установка» приложений. Программная линейка FineReader, помимо рассмотренных версий, содержит более мощный продукт — ABBYY FineReader 8.0 Corporate Edition (7400 рублей) для работы в локальной корпоративной сети, и обладающий всеми функциональными возможностями версии Professional.
FineReader 8.0 Corporate Edition рассчитан не только на автоматическую установку по локальной сети, но и работу с сетевыми сканерами и многофункциональными устройствами*, которыми могут пользоваться все сотрудники организации. Благодаря специальным настройкам корпоративной версии FineReader 8.0 работник может заставить программу сделать так, чтобы отсканированные им документы были автоматически открыты и распознаны именно на конкретной рабочей станции.
По большому счету, дополнительные возможности корпоративной версии сводятся к эффективной организации коллективной работы в сети: на одном компьютере документ сканируется, на другом — распознается, а на третьем происходит проверка результатов. Кроме того, можно совместно работать по сети с пользовательскими языками и словарями. Безусловно, данная модификация программы актуальна для организаций с большим объемом документооборота.
Этот продукт стоит несколько особняком. Программа умеет только одно: конвертировать PDF-документы в форматы, позволяющие редактировать информацию. Софтина работает со всеми типами PDF-файлов, сохраняя при этом внешний вид несложно оформленного документа: таблицы, картинки, колонки и заголовки.
Испытательная версия программы (41 Мбайт) загружается с сайта компании, правда, вас ждут определенные ограничения: конвертации подлежат лишь 15 PDF-файлов, а для многостраничного PDF-документа можно конвертировать только 3 страницы на выбор. Что делать дальше, вы знаете: готовьте 830 рублей и полная версия у вас в кармане.
Предлагается 10 языков установки, а также интеграция не только со всеми программами MS Office, но и с системным «Проводником». По окончании инсталляции на «Рабочем столе» появится значок «Мастер конвертирования ABBYY PDF Transformer». Да, уважаемые читатели, нас вновь встретит «Мастер», а следовательно и несколько последовательных шагов (рис. 19).
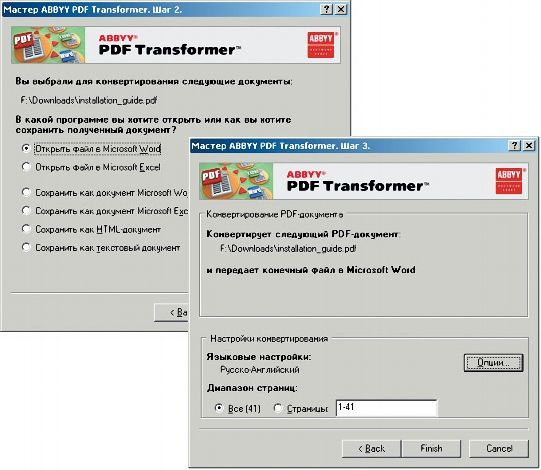 |
Идеологическим противникам «Мастера» предлагается группа команд PDF Transformer контекстного меню: щелкаем правой кнопкой по PDF-файлу и выбираем нужную команду — например, «Сохранить как DOC/RTF» (рис. 20).
 |
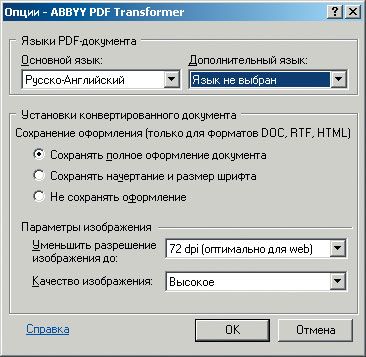
Только не забудьте в окне выбора PDF-файла нажать кнопку «Опции» для выбора языков документа и параметров графики (рис. 21).
 |
| © 2024 Библиотека RealLib.org (support [a t] reallib.org) |