"4.Внутреннее устройство Windows (гл. 12-14)" - читать интересную книгу автора (Руссинович Марк, Соломон Дэвид)
М.Руссинович, Д.Соломон Внутреннее устройство Microsoft Windows (главы 12–14)
ГЛABA 12 Файловые системы
B начале этой главы мы даем обзор файловых систем, поддерживаемых Windows, а также описываем типы драйверов файловых систем и принципы их работы, в том числе способы взаимодействия с другими компонентами операционной системы, например с диспетчерами памяти и кэша. Затем поясняем, как пользоваться утилитой Filemon
Чтобы полностью усвоить материал этой главы, вы должны понимать терминологию, введенную в главе 10, в том числе термины «том» и «раздел». Кроме того, вам должны быть знакомы следующие дополнительные термины.
•
•
•
 |
•
Windows поддерживает файловые системы:
• CDFS;
• UDF;
• FAT12, FATl6 и FAT32;
• NTFS.
Как вы еще увидите, каждая из этих файловых систем оптимальна для определенной среды.
CDFS, или файловая система CD-ROM (только для чтения), обслуживается драйвером \Windows\System32\Drivers\Cdfs.sys, который поддерживает надмножества форматов ISO-9660 и Joliet. Если формат ISO-9660 сравнительно прост и имеет ряд ограничений, например имена с буквами верхнего регистра в кодировке ASCII и максимальной длиной в 32 символа, то формат Joliet более гибок и поддерживает Unicode-имена произвольной длины. Если на диске присутствуют структуры для обоих форматов (чтобы обеспечить максимальную совместимость), CDFS использует формат Joilet. CDFS присущ ряд ограничений:
• максимальная длина файлов не должна превышать 4 Гб;
• число каталогов не может превышать 65 535.
CDFS считается унаследованным форматом, поскольку индустрия уже приняла в качестве стандарта для носителей, предназначенных только для чтения, формат Universal Disk Format (UDF).
Файловая система UDF в Windows является UDF-совместимой реализацией OSTA (Optical Storage Technology Association). (UDF является подмножеством формата ISO-13346 с расширениями для поддержки CD-R, DVD-R/RW и т. д.) OSTA определила UDF в 1995 году как формат магнитооптических носителей, главным образом DVD-ROM, предназначенный для замены формата ISO-9660. UDF включен в спецификацию DVD и более гибок, чем CDFS. Драйвер UDF поддерживает UDF версий 1.02 и 1.5 в Windows 2000, а также версий 2.0 и 2.01 в Windows XP и Windows Server 2003. Файловые системы UDF обладают следующими преимуществами:
• длина имен файлов и каталогов может быть до 254 символов в ASCII-кодировке или до 127 символов в Unicode-кодировке;
• файлы могут быть разреженными (sparse);
• размеры файлов задаются 64-битными значениями.
Хотя формат UDF разрабатывался с учетом особенностей перезаписываемых носителей, драйвер UDF в Windows (\Windows\System32\Drivers\ Udfs.sys) поддерживает носители только для чтения. Кроме того, в Windows не реализована поддержка других возможностей UDF, в частности именованных потоков, списков управления доступом и расширенных атрибутов.
Windows поддерживает файловую систему FAT по трем причинам: для возможности обновления операционной системы с прежних версий Windows до современных, для совместимости с другими операционными системами при многовариантной загрузке и как формат гибких дисков. Драйвер файловой системы FAT в Windows реализован в \Windows\System32\Drivers\ Fastfat.sys.
B название каждого формата FAT входит число, которое указывает разрядность, применяемую для идентификации кластеров на диске. 12-разрядный идентификатор кластеров в FAT12 ограничивает размер дискового раздела 212 (4096) кластерами. B Windows используются кластеры размером от 512 байтов до 8 Кб, так что размер тома FAT12 ограничен 32 Мб. Поэтому Windows использует FAT12 как формат 5- и 3,5-дюймовых дискет, способных хранить до 1,44 Мб данных.
FATl6 — за счет 16-разрядных идентификаторов кластеров — может адресовать до 216 (65 536) кластеров. B Windows размер кластера FATl6 варьируется от 512 байтов до 64 Кб, поэтому размер FATl6-TOMa ограничен 4 Гб. Размер кластеров, используемых Windows, зависит от размера тома (таблица 12-1). Если вы форматируете том размером менее 16 Мб для FAT с помощью команды
 |
Том FAT делится на несколько областей (рис. 12-2). Таблица размещения файлов (file allocation table, FAT), от которой и произошло название файловой системы FAT, имеет по одной записи для каждого кластера тома. Поскольку таблица размещения файлов критична для успешной интерпретации содержимого тома, FAT поддерживает две копии этой таблицы. Так что, если драйвер файловой системы или программа проверки целостности диска (вроде Chkdsk) не сумеет получить доступ к одной из копий FAT (например, из-за плохого сектора на диске), она сможет использовать вторую копию.
 |
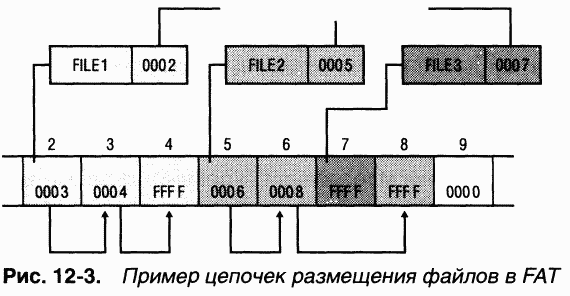
Записи в таблице FAT определяют цепочки размещения файлов и каталогов (рис. 12-3), где отдельные звенья представляют собой указатели на следующий кластер с данными файла. Элемент каталога для файла хранит начальный кластер файла. Последний элемент цепочки размещения файла содержит зарезервированное значение 0xFFFF для FATl6 и 0xFFF для FATl 2. Записи FAT, описывающие свободные кластеры, содержат нулевые значения. Ha рис. 12-3 показан файл FILE1, которому назначены кластеры 2, 3 и 4; FILE2 фрагментирован и использует кластеры 5, 6 и 8; a FILE3 занимает только кластер 7. Чтение файла с FAT-тома может потребовать просмотра больших блоков таблицы размещения файлов для поиска всех его цепочек размещения.
 |
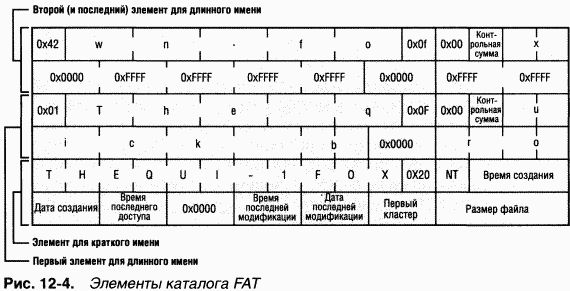
B начале тома FAT12 или FATl6 заранее выделяется место для корневого каталога, достаточное для хранения 256 записей (элементов), что ограничивает число файлов и каталогов в корневом каталоге (в FAT32 такого ограничения нет). Элемент каталога FAT, размер которого составляет 32 байта, хранит имя файла, его размер, начальный кластер и метку времени (время создания, последнего доступа и т. д.). Если имя файла состоит из Unicode-символов или не соответствует правилам именования по формуле «8.3», принятым в MS-DOS, оно считается длинным и для его хранения выделяются дополнительные элементы каталога. Вспомогательные элементы предшествуют главному элементу для файла. Ha рис. 12-4 показан пример элемента каталога для файла с именем «The quick brown fox». Система создала представление этого имени в формате «8.3», THEQUI~l.FOX (в элементе каталога вы не увидите «.», поскольку предполагается, что точка следует после восьмого символа), и использовала два дополнительных элемента для хранения длинного Unicode-имени. Каждая строка на рис. 12-4 состоит из 16 байтов.
 |
FAT32 — более новая файловая система на основе формата FAT; она поддерживается Windows 95 OSR2, Windows 98 и Windows Millennium Edition. FAT32 использует 32-разрядные идентификаторы кластеров, но при этом резервирует старшие 4 бита, так что эффективный размер идентификатора кластера составляет 28 бит. Поскольку максимальный размер кластеров FAT32 равен 32 Кб, теоретически FAT32 может работать с 8-терабайтными томами. Windows ограничивает размер новых томов FAT32 до 32 Гб, хотя поддерживает существующие тома FAT32 большего размера (созданные в других операционных системах). Большее число кластеров, поддерживаемое FAT32, позволяет ей управлять дисками более эффективно, чем FATl6. FAT32 может использовать 512-байтовые кластеры для томов размером до 128 Мб. Размеры кластеров на томах FAT32 по умолчанию показаны в таблице 12-2.
 |
Помимо большего предельного числа кластеров преимуществом FAT32 перед FAT12 и FATl6 является тот факт, что место хранения корневого каталога FAT32 не ограничено предопределенной областью тома, поэтому его размер не ограничен. Кроме того, для большей надежности FAT32 хранит вторую копию загрузочного сектора*. B FAT32, как и в FATl6, максимальный размер файла равен 4 Гб, посколькудлина файла в каталоге описывается 32-битным числом.
Как мы уже говорили в начале главы, NTFS — встроенная («родная») файловая система Windows. NTFS использует 64-разрядные номера кластеров. Это позволяет NTFS адресовать тома размером до 16 экзабайт (16 миллиардов Гб). Однако Windows ограничивает размеры томов NTFS до значений, при которых возможна адресация 32-разрядными кластерами, т. е. до 128 Тб (с использованием кластеров по 64 Кб). B таблице 12-3 перечислены размеры кластеров на томах NTFS по умолчанию (эти значения можно изменить при форматировании тома NTFS).
 |
NTFS поддерживает ряд дополнительных возможностей — защиту файлов и каталогов, дисковые квоты, сжатие файлов, символьные ссылки на основе каталогов и шифрование. Одно из важнейших свойств NTFS —
* Точнее — загрузочной записи, которая включает несколько секторов. Подробную информацию о FAT32 см. в книге «Ресурсы Microsoft Windows 98». —
Подробнее о структурах данных и дополнительных возможностях NTFS мы поговорим позже.
Драйвер файловой системы (file system driver, FSD) управляет форматом файловой системы. Хотя FSD выполняются в режиме ядра, у них есть целый ряд особенностей по сравнению со стандартными драйверами режима ядра. Возможно, самой важной особенностью является то, что они должны регистрироваться у диспетчера ввода-вывода и более интенсивно взаимодействовать с ним. Кроме того, для большей производительности FSD обычно полагаются на сервисы диспетчера кэша. Таким образом, FSD используют более широкий набор функций, экспортируемых Ntoskrnl, чем стандартные драйверы. Если для создания стандартных драйверов режима ядра требуется Windows DDK, то для создания драйверов файловых систем понадобится Windows Installable File System (IFS) Kit (подробнее o DDK см. главу 1; подробнее о IFS Kit см.
•
•
K локальным FSD относятся Ntfs.sys, Fastfat.sys, Udfs.sys, Cdfs.sys и Raw FSD (интегрированный в Ntoskrnl.exe). Ha рис. 12-5 показана упрощенная схема взаимодействия локальных FSD с диспетчером ввода-вывода и драйверами устройств внешней памяти. Как мы поясняли в разделе «Монтирование томов» главы 10, локальный FSD должен зарегистрироваться у диспетчера ввода-вывода. После регистрации FSD диспетчер ввода-вывода может вызывать его для распознавания томов при первом обращении к ним системы или одного из приложений. Процесс распознавания включает анализ загрузочного сектора тома и, как правило, метаданных файловой системы для проверки ее целостности.
Все поддерживаемые Windows файловые системы резервируют первый сектор тома как загрузочный. Загрузочный сектор содержит достаточно информации, чтобы FSD мог идентифицировать свой формат файловой системы тома и найти любые метаданные, хранящиеся на этом томе.
Распознав том, FSD создает объект «устройство», представляющий смонтированную файловую систему. Диспетчер ввода-вывода связывает объект «устройство» тома, созданный драйвером устройства внешней памяти (далее — объект тома), с объектом «устройство», созданным FSD (далее — объект FSD), через блок параметров тома (VPB). Это приводит к тому, что диспетчер ввода-вывода перенаправляет через VPB запросы ввода-вывода, адресованные объекту тома, на объект FSD (подробнее о VPB см. главу 10).
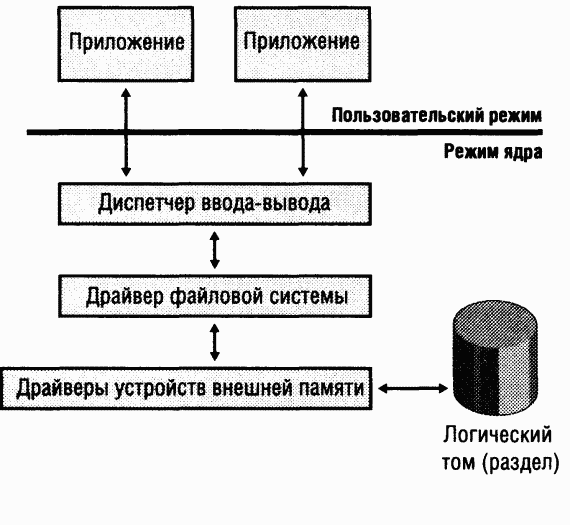 |
Рис. 12-5.
Для большей производительности локальные FSD обычно используют диспетчер кэша, который кэширует данные файловой системы, в том числе ее метаданные. Они также интегрируются с диспетчером памяти, что позволяет корректно реализовать проецирование файлов. Например, всякий раз, когда приложение пытается обрезать файл, они должны запрашивать диспетчер памяти, чтобы убедиться, что за точкой отсечения файл не проецируется ни одним процессом. Windows не разрешает удалять данные файла, проецируемого приложением.
Локальные FSD также поддерживают операции демонтирования файловой системы, позволяющие операционной системе отсоединять FSD от объекта тома. Демонтирование происходит каждый раз, когда приложение напрямую обращается к содержимому тома или когда происходит смена носителя, сопоставленного с томом. При первом обращении приложения к носителю после демонтирования диспетчер ввода-вывода повторно инициирует операцию монтирования тома для этого носителя.
Удаленные FSD состоят из двух компонентов: клиента и сервера. Удаленный FSD на клиентской стороне позволяет приложениям обращаться к удаленным файлам и каталогам. Клиентский FSD принимает запросы ввода-вывода от приложений и транслирует их в команды протокола сетевой файловой системы, посылаемые через сеть компоненту на серверной стороне, которым обычно является удаленный FSD. Серверный FSD принимает команды, поступающие по сетевому соединению, и выполняет их. При этом он выдает запросы на ввод-вывод локальному FSD, управляющему томом, на котором расположен нужный файл или каталог.
Windows включает клиентский удаленный FSD, LANMan Redirector (редиректор), и серверный удаленный FSD, LANMan Server (сервер) (\Windows\ System32\Drivers\Srv.sys). Редиректор реализован в виде комбинации порт- и минипорт-драйверов, где порт-драйвер (\Windows\System32\Drivers \Rdbss.sys) представляет собой библиотеку подпрограмм, а минипорт-драйвер (\Windows\System32\Drivers\Mrxsmb.sys) использует сервисы, реализуемые порт-драйвером. Еще один минипорт-драйвер редиректора — WebDAV (\Win-dows\System32\Drivers\Mrxdav.sys), который реализует клиентскую часть поддержки доступа к файлам по HTTR Модель «порт-минипорт» упрощает разработку редиректора, потому что порт-драйвер, совместно используемый всеми минипорт-драйверами удаленных FSD, берет на себя многие рутинные операции, требуемые при взаимодействии между клиентским FSD и диспетчером ввода-вывода Windows. B дополнение к FSD-компонентам LANMan Redirector и LANMan Server включают Windows-службы рабочей станции и сервера соответственно. Взаимодействие между клиентом и сервером при доступе к файлам на серверной стороне через редиректор и серверные FSD показано на рис. 12-6.
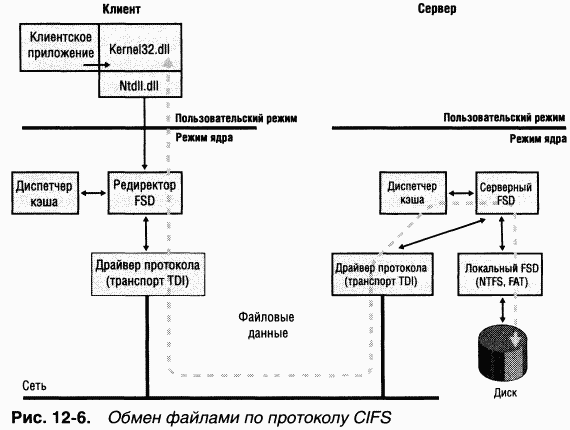 |
Для форматирования сообщений, которыми обмениваются редиректор и сервер, Windows использует протокол CIFS (Common Internet File System). CIFS — это версия протокола Microsoft SMB (Server Message Block). (Подробнее o CIFS см. книгу «Сети TCP/IP. Ресурсы Microsoft Windows 2000 Server» и сайт
Как и локальные FSD, удаленные FSD на клиентской стороне обычно используют сервисы диспетчера кэша для локального кэширования файловых данных, относящихся к удаленным файлам и каталогам. Однако удаленный FSD на клиентской стороне должен реализовать протокол поддержки когерентности распределенного кэша, называемый
Когда клиент пытается обратиться к файлу на сервере, он должен сначала запросить oplock. Вид доступного клиенту кэширования, определяется типом oplock, предоставляемого сервером. Существует три основных типа oplock.
• Level I oplock предоставляется при монопольном доступе клиента к файлу Клиент, удерживающий для файла oplock этого типа, может кэшировать операции как чтения, так и записи.
• Level II oplock — разделяемая блокировка файла. Клиенты, удерживающие oplock этого типа, могут кэшировать операции чтения, но запись в файл делает Level II oplock недействительным.
• Batch oplock — самый либеральный тип oplock. Он позволяет клиенту не только читать и записывать файл, но и открывать и закрывать его, не запрашивая дополнительные oplock. Batch oplock, как правило, используется только для поддержки выполнения пакетных (командных) файлов, которые могут неоднократно закрываться и открываться в процессе выполнения.
B отсутствие oplock клиент не может осуществлять локальное кэширование ни операций чтения, ни операций записи; вместо этого он должен получать данные с сервера и посылать все изменения непосредственно на сервер.
Проиллюстрировать работу oplock поможет пример на рис. 12-7. Первому клиенту, открывающему файл, сервер автоматически предоставляет Level I oplock. Редиректор на клиентской стороне кэширует файловые данные при чтении и записи в кэше файловой системы локальной машины. Если тот же файл открывает второй клиент, он также запрашивает Level I oplock. Теперь уже два клиента обращаются к одному и тому же файлу, поэтому сервер должен принять меры для согласования представления данных файла обоим клиентам. Если первый клиент произвел запись в файл (этот случай и показан на рис. 12-7), сервер отзывает oplock и больше не предоставляет его ни одному клиенту. После отзыва oplock первый клиент сбрасывает все кэшированные данные файла обратно на сервер.
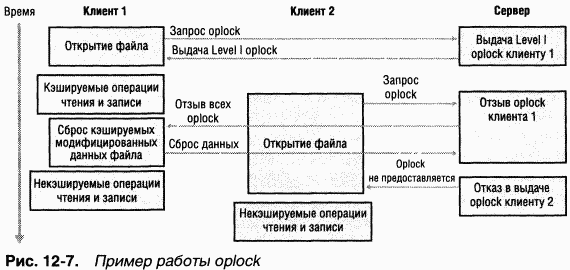 |
Если бы первый клиент не произвел запись, его oplock был бы понижен до Level II oplock, т. е. до oplock того же типа, который сервер предоставляет второму клиенту. B этом случае оба клиента могли бы кэшировать операции чтения, но после операции записи любым из клиентов сервер отозвал бы их oplock, и последующие операции были бы некэшируемыми. Однажды отозванный, oplock больше не предоставляется для этого экземпляра открытого файла. Однако, если клиент закрывает файл и повторно открывает его, сервер заново решает, какой oplock следует предоставить клиенту. Решение сервера зависит от того, открыт ли файл другими клиентами и производил ли хоть один из них запись в этот файл.
ЭКСПЕРИМЕНТ: просмотр списка зарегистрированных файловых систем
Диспетчер ввода-вывода, загружая в память драйвер устройства, обычно присваивает имя объекту «драйвер», который создается для представления этого драйвера. Этот объект помещается в каталог \Drivers диспетчера объектов. Объекты «драйвер» любого загружаемого диспетчером ввода-вывода драйвера с атрибутом Туре, равным SERVICEFILE _SYSTEM_DRIVER (2), помещаются этим диспетчером в каталог \File-System. Таким образом, утилита типа Winobj
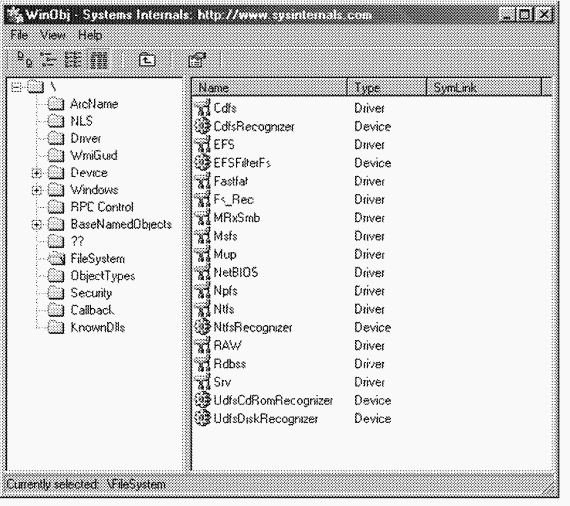 |
Еще один способ увидеть зарегистрированные файловые системы — запустить программу System Information (Сведения о системе). B Windows 2000 запустите оснастку Computer Management (Управление компьютером) и выберите Drivers (Драйверы) в Software Environment (Программная среда) в узле System Information (Сведения о системе); в Windows XP и Windows Server 2003 запустите Msinfo32 и выберите System Drivers (Системные драйверы) в узле Software Environment (Программная среда). Отсортируйте список драйверов, щелкнув колонку Туре (Тип), и драйверы с атрибутом SERVICE_FILE_SYSTEM_DRIVER окажутся в начале списка.
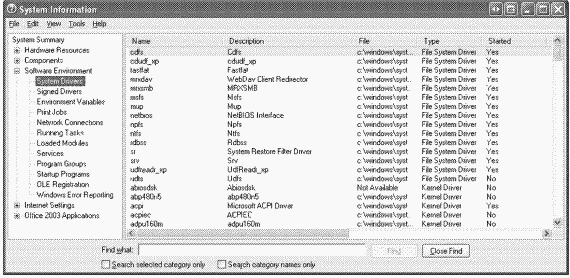 |
Заметьте: если драйвер регистрируется как SERVICE_FILE_SYSTEM_DRIVER, это еще не означает, что он служит локальным или удаленным FSD. Например, Npfs (Named Pipe File System), присутствующий на только что показанной иллюстрации, на самом деле является драйвером сетевого API — он поддерживает именованные каналы, но реализует закрытое пространство имен и поэтому в какой-то мере подобен драйверу файловой системы. Пространство имен Npfs исследуется в одном из экспериментов в главе 13.
Система и приложения могут обращаться к файлам двумя способами: напрямую (через функции ввода-вывода вроде
• из пользовательского или системного потока, выполняющего явную операцию файлового ввода-вывода;
• из подсистем записи модифицированных и спроецированных страниц, принадлежащих диспетчеру памяти;
• неявно из подсистемы отложенной записи, принадлежащей диспетчеру кэша;
• неявно из потока опережающего чтения, принадлежащего диспетчеру кэша;
• из обработчика ошибок страниц, принадлежащего диспетчеру памяти.
 |
Наиболее очевидный способ доступа приложения к файлам — вызов Windows-функций ввода-вывода, например
Чтобы открыть файл, системный сервис
Первое, что делает диспетчер объектов, — транслирует \?? в каталог пространства имен, индивидуальный для сеанса, в котором выполняется данный процесс; на этот каталог ссылается поле
Символьная ссылка для буквы диска, присвоенной тому, указывает на объект тома в каталоге \Device, поэтому диспетчер объектов, распознав объект тома, передает остаток строки с именем в функцию
 |
Заблокировав контекст защиты вызывающего потока и получив информацию о защите из его маркера,
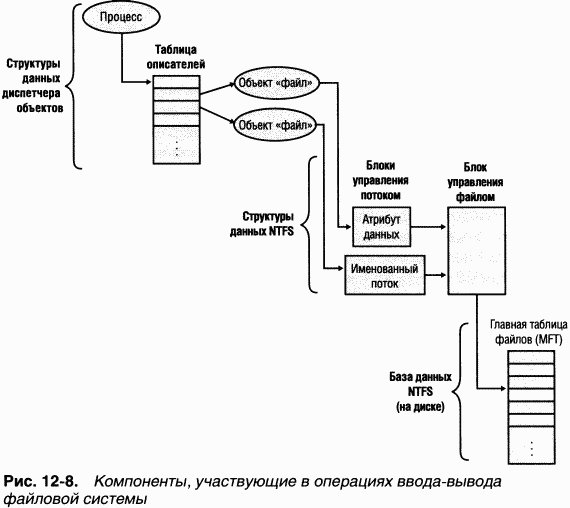
Когда FSD получает IRP типа IRP_MJ_CREATE, он ищет указанный файл, проверяет права доступа и, если файл есть и пользователь имеет права на запрошенный вид доступа к файлу, возвращает код успешного завершения. Диспетчер объектов создает в таблице описателей, принадлежащей процессу, описатель объекта «файл», который передается назад по цепочке вызовов, в конечном счете достигая приложения в виде параметра, возвращаемого
Мы опустили здесь детали, относящиеся к тому, как FSD находит открываемый на томе файл. B выполнении
Если считываемый файл может быть кэширован (т. е. при открытии файла в функцию
Убедившись, что кэширование файла разрешено, FSD копирует данные запрошенного файла из виртуальной памяти диспетчера кэша в буфер, указатель на который передан функции
Диспетчер кэша, выполняя
Когда возникает ошибка страницы,
Найдя объект «файл»,
Диспетчер виртуальной памяти ждет, когда FSD завершит чтение, а потом возвращает управление диспетчеру кэша, который продолжает операцию копирования, прерванную ошибкой страницы. По окончании работы
Если файловые данные уже хранятся в системном рабочем наборе, вышеописанный сценарий немного меняется. Если файловые данные находятся в кэше,
B большинстве FSD точки быстрого ввода-вывода вызывают в диспетчере кэша функции
Для сброса модифицированных страниц при нехватке доступной памяти периодически пробуждаются потоки принадлежащих диспетчеру памяти подсистем записи модифицированных и спроецированных страниц. Эти потоки вызывают функцию
Поток подсистемы отложенной записи, принадлежащей диспетчеру кэша, тоже участвует в записи модифицированных страниц, поскольку периодически сбрасывает на диск измененные представления разделов файлов, проецируемых на кэш. Операция сброса, выполняемая диспетчером кэша вызовом
Диспетчер кэша включает поток, отвечающий за попытку чтения данных из файлов до того, как их явным образом запросит приложение, драйвер или системный поток. Чтобы определить объем подлежащих чтению данных, поток опережающего чтения использует хронологию операций чтения, которая хранится в закрытой карте кэша объекта «файл». Выполняя опережающее чтение, этот поток просто проецирует на кэш ту часть файла, которую он хочет считать (при необходимости создавая VACB), и обращается к спроецированным данным. Если при попытках обращения возникают ошибки страниц, активизируется обработчик ошибок страниц, который подгружает нужные страницы в системный рабочий набор.
Мы описывали использование обработчика ошибок страниц в контексте явного файлового ввода-вывода и опережающего чтения диспетчера кэша. Ho этот обработчик активизируется и всякий раз, когда приложение обращается к виртуальной памяти, являющейся представлением проецируемого файла, и встречает страницы, которые представляют часть файла, но не входят в рабочий набор приложения. Обработчик
Драйвер фильтра, занимающий в иерархии более высокий уровень, чем драйвер файловой системы, называется
B этом разделе мы опишем работу двух специфических драйверов фильтров файловой системы: Filemon и System Restore. Filemon — утилита для мониторинга активности файловой системы (с сайта
Утилита Filemon извлекает драйвер устройства «фильтр файловой системы» (Filem.sys) из своего исполняемого образа (Filemon.exe) при первом ее запуске после загрузки, устанавливает этот драйвер в памяти, а затем удаляет его образ с диска. Через GUI утилиты Filemon вы можете указывать ей вести мониторинг активности файловой системы на локальных томах, общих сетевых ресурсах, именованных каналах и почтовых ящиках (mail slots). Получив команду начать мониторинг тома, драйвер создает объект «устройство» фильтра и подключает его к объекту «устройству», который представляет смонтированную файловую систему на томе. Например, если драйвер NTFS смонтировал том, драйвер Filemon подключит к объекту «устройство» данного тома свой объект «устройство», используя функцию
Перехватив IRP, драйвер Filemon записывает информацию о команде в этом IRP, в том числе имя целевого файла и другие параметры, специфичные для команды (например, размер и смещение считываемых или записываемых данных), в буфер режима ядра, созданный в неподкачиваемой памяти. Дважды в секунду Filemon GUI посылает IRP объекту «устройство» интерфейса Filemon, который запрашивает копию буфера, содержащего сведения о самых последних операциях, и отображает их в окне вывода. Применение Filemon подробно описывается в разделе «Анализ проблем в файловой системе» далее в этой главе.
System Restore (Восстановление системы) — сервис, в рудиментарной форме впервые появившийся в Windows Me (Millennium Edition), позволяет восстанавливать систему до предыдущего известного состояния в ситуациях, в которых иначе пришлось бы переустанавливать какое-то приложение или даже всю операционную систему. (System Restore нет в Windows 2000 и Windows Server 2003) Например, если вы установили одно или несколько приложений или внесли какие-то изменения в реестр либо системный файл и это вызвало проблемы в работе приложений или крах системы, вы можете использовать System Restore для отката системных файлов и реестра в предыдущее состояние. System Restore особенно полезен, когда вы устанавливаете приложение, вносящее нежелательные изменения в системные файлы. Программы установки, совместимые с Windows XP, интегрируются с System Restore и создают точку восстановления до начала процесса установки.
Ядро System Restore содержится в сервисе SrService, который вызывается из DLL (\Windows\System32\Srsvc.dll), выполняемой в экземпляре универсального процесса — хоста сервисов (\Windows\System32\Svchost.exe). (Описание Svchost см. в главе 4.) Роль этого сервиса заключается как в автоматическом создании точек восстановления, так и в экспорте соответствующего API другим приложениям, например программам установки. (Кстати, вы можете вручную инициировать создание точки восстановления.) System Restore считывает свои конфигурационные параметры из раздела реестра HKLM\System\ CurrentControlSet\Services\SR\Parameters, в том числе указывающие, сколько места на диске должно быть свободно для работы этого сервиса и через какой интервал следует автоматически создавать точки восстановления. По умолчанию данный сервис создает точку восстановления перед установкой неподписанного драйвера устройства и через каждые 24 часа работы системы. Если в упомянутом выше разделе реестра задан DWORD-параметр RPGIobalInterval, он переопределяет этот интервал и задает минимальное время в секундах между моментами автоматического создания точек восстановления.
Создавая новую точку восстановления, сервис System Restore сначала создает каталог для этой точки, затем делает снимок состояния критически важных системных файлов, включая кусты реестра, относящиеся к системе и пользовательским профилям, конфигурационную информацию WMI, файл метабазы IIS (если IIS установлена) и регистрационную базу данных СОМ. Потом драйвер восстановления системы, \Windows\System32\Drivers \Sr.sys, начинает отслеживать изменения в файлах и каталогах, сохраняя копии удаляемых или модифицируемых файлов в точке восстановления, а также отмечая другие изменения, например создание и удаление каталогов, в журнале регистрации изменений.
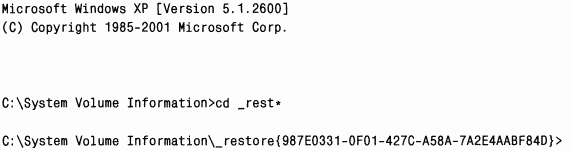
Данные точки восстановления поддерживаются для каждого тома индивидуально, поэтому журналы изменений и сохраненные файлы хранятся в каталогах \System Volume Information\_restore{XX–XXX–XXX), где символы
Резервным копиям файлов, созданным драйвером System Restore, присваиваются уникальные имена (вроде A0000135.dll), и эти файлы помещаются в соответствующий каталог. C точкой восстановления может быть сопоставлено несколько журналов изменений, каждый из которых получает имя в виде Change.log.N, где
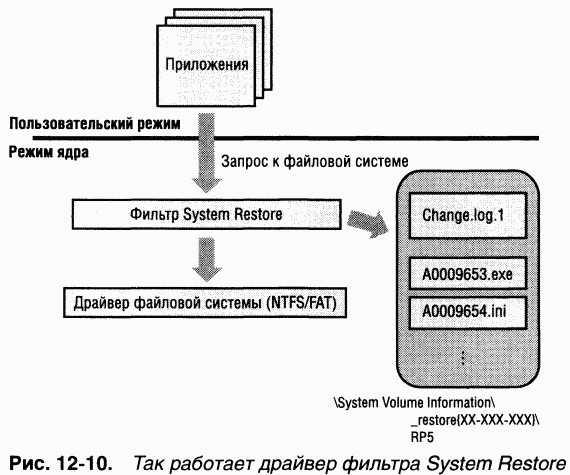 |
Рис. 12–11 иллюстрирует содержимое каталога, созданного System Restore и включающего несколько подкаталогов точек восстановления, а также содержимое подкаталога, который соответствует точке восстановления 1. Заметьте, что каталоги \System Volume Information недоступны ни по пользовательской учетной записи, ни по учетной записи администратора — к ним можно обращаться только по учетной записи Local System. Чтобы увидеть этот каталог, используйте утилиту PsExec с сайта
 |
 |
Попав в каталог System Restore, вы можете просмотреть его содержимое командой DIR или перейти в подкаталоги, сопоставленные с точками восстановления.
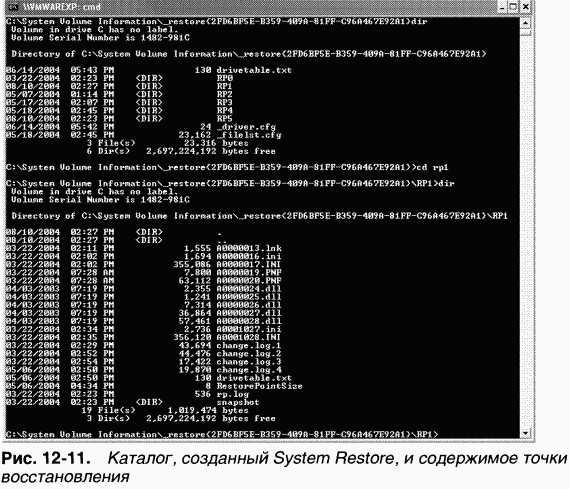 |
Каталог точки восстановления на загрузочном томе также содержит двоичный файл _filelst.cfg, который включает расширения файлов, изменения в которых следует фиксировать в точке восстановления, и список каталогов (хранящих, например, временные файлы), изменения в которых следует игнорировать. Этот список, документированный в Platform SDK, указывает System Restore отслеживать только файлы, отличные от файлов данных. (Вряд ли вам понравится, если при откате системы из-за проблемы с каким-нибудь приложением сервис System Restore удалит важный для вас документ Microsoft Word.)
ЭКСПЕРИМЕНТ: изучение объектов «устройство», принадлежащих фильтру System Restore
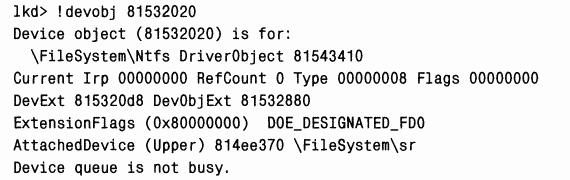
Для мониторинга изменений в файлах и каталогах драйвер фильтра System Restore должен подключить объекты «устройство» фильтра к объектам «устройство» FAT и NTFS, представляющим тома. Кроме того, он подключает объект «устройство» фильтра к объектам «устройство», представляющим драйверы файловой системы, чтобы узнавать о монтировании новых томов файловой системой и соответственно подключать к ним объекты «устройство» фильтра. Объекты «устройство» System Restore можно просмотреть с помощью отладчика ядра:
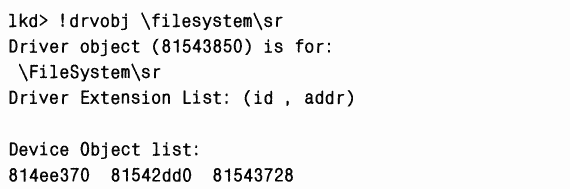 |
B этом примере вывода у драйвера System Restore три объекта «устройство». Последний из них в списке называется
 |
Первый и второй объекты подключены к объектам «устройство» файловой системы NTFS:
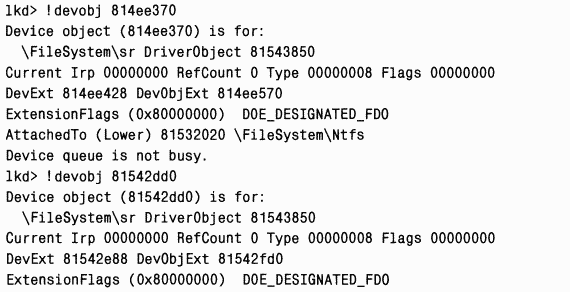 |
 |
Один из объектов «устройство» NTFS является интерфейсом для драйвера файловой системы NTFS, так как его имя —
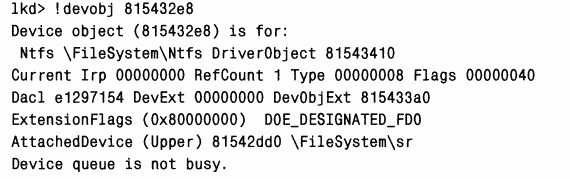 |
Другой из них представляет смонтированный NTFS-том на C:, и, поскольку в системе только один том, у этого объекта нет имени:
 |
Когда пользователь сообщает системе о необходимости восстановления, мастер System Restore (\Windows\System32\Restore\Rstrui.exe) создает параметр RestoreInProgress типа DWORD в разделе реестра System Restore и присваивает ему значение 1. Затем он инициирует перезагрузку системы, вызывая Windows-функцию
B Platform SDK документированы две API-функции System Restore,
B главе 4 было показано, как система и приложения хранят данные в реестре. Если в реестре появляются какие-то проблемы, скажем, из-за неправильно сконфигурированной защиты или недостающих параметров/разделов реестра, то они могут быть причиной многих сбоев в работе системы и приложений. Помимо этого, система и приложения используют файлы для хранения данных и обращаются к образам DLL и исполняемых файлов. Значит, ошибки в конфигурации защиты NTFS и отсутствие каких-либо файлов или каталогов также являются распространенной причиной сбоев в работе системы и приложений. A все потому, что система и приложения часто полагаются на возможность беспрепятственного доступа к таким файлам и начинают вести себя непредсказуемым образом, если эти файлы оказываются недоступны.
Утилита Filemon отражает все файловые операции по мере их выполнения, что превращает ее в идеальный инструмент для анализа сбоев системы и приложений из-за проблем в файловой системе. Пользовательский интерфейс Filemon практически идентичен таковому в Regmon, и Filemon включает те же средства фильтрации, выделения и поиска, что и Regmon. Первый запуск Filemon в системе требует учетной записи с теми же привилегиями, что и в случае Regmon: Load Driver и Debug. После загрузки драйвер остается резидентным в памяти, поэтому для последующих запусков Filemon достаточно привилегии Debug.
При запуске Filemon начинает работу в базовом режиме, в котором отображаются те операции в файловой системе, которые наиболее полезны для анализа проблем. B этом режиме Filemon не показывает определенные операции в файловой системе, в том числе:
• обращения к файлам метаданных NTFS;
• операции в процессе System;
• ввод-вывод, связанный со страничным файлом;
• ввод-вывод, генерируемый процессом Filemon;
• неудачные попытки быстрого ввода-вывода.
Кроме того, в базовом режиме Filemon сообщает об операциях файлового ввода-вывода, используя описательные имена, а не типы IRP, которые на самом деле представляют их. B частности, операции IRP_MJ_WRITE и FASTIO_ WRITE отображаются как Write, а операции IRP_MJ_CREATE — как Open (при открытии существующих файлов) или Create (при создании новых файлов).
ЭКСПЕРИМЕНТ: наблюдение за активностью файловой системы в простаивающей системе
Драйверы файловых систем Windows поддерживают
Запустите Filemon и через несколько секунд проверьте в журнале вывода, есть ли попытки периодического опроса. Обнаружив соответствующую строку, щелкните ее правой кнопкой мыши и выберите из контекстного меню Process Properties для просмотра детальных сведений о процессе, который выполняет операции опроса.
Два основных метода анализа проблем с применением Filemon идентичны таковым при использовании Regmon: поиск последней операции в трассировочной информации Filemon перед тем, как в приложении произошел сбой, или сравнение трассировочной информации Filemon для сбойного приложения с аналогичными сведениями для работающей системы. Подробнее об этих способах см. раздел «Методики анализа проблем с применением Regmon» главы 4.
Обращайте внимание на записи в выводе Filemon со значениями FILE NOT FOUND, NO SUCH FILE, PATH NOT FOUND, SHARING VIOLATION и ACCESS DENIED в столбце Result. Первые три значения указывают на то, что приложение или система пытается открыть несуществующий файл или каталог. Bo многих случаях эти ошибки не свидетельствуют о серьезной проблеме. Например, если вы запускаете какую-то программу из диалогового окна Run (Запуск программы), не задавая полный путь к ней, Explorer будет искать эту программу в каталогах, перечисленных в переменной окружения PATH, пока не найдет нужный образ или не закончит просмотр всех перечисленных каталогов. Каждая попытка найти образ в каталоге, где такого образа нет, отражается в выводе Filemon строкой, аналогичной приведенной ниже:
 |
Ошибки, связанные с отклонением попыток доступа, — частая причина сбоев приложений при работе с файловой системой, и они возникают, когда у приложения нет соответствующего разрешения на открытие файла или каталога. Некоторые приложения не проверяют коды ошибок или не обрабатывают ошибки, из-за чего происходит их крах или аварийное завершение, а некоторые выводят при этом сообщения о других ошибках, которые лишь маскируют истинную причину неудачи файловой операции.
Прорехи в защите из-за переполнения буфера представляют серьезную угрозу безопасности, но код результата BUFFER OVERFLOW — просто способ, используемый драйвером файловой системы, чтобы сообщить приложению о нехватке места в выделенном буфере для сохранения полученных данных. Разработчики приложений применяют этот способ, чтобы определить правильный размер буфера, так как драйвер файловой системы заодно сообщает и эту информацию. За операциями с кодом результата BUFFER OVERFLOW обычно следуют операции с успешным результатом.
ЭКСПЕРИМЕНТ: выявление истинной причины ошибки с помощью Filemon
Иногда приложения выводят сообщения об ошибках, которые не раскрывают истинную причину проблемы. Такие сообщения могут запутать и заставить вас тратить время на диагностику несуществующих проблем. Если сообщение об ошибке относится к проблеме в файловой системе, Filemon покажет, какие нижележащие ошибки могли бы предшествовать этому сообщению.
B данном эксперименте вы установите разрешение для каталога, а затем попытаетесь выполнить в нем операцию сохранения файла из Notepad, что приведет к появлению сообщения о совсем другой ошибке. Filemon покажет истинную ошибку и причину вывода в Notepad именно такого сообщения.
1. Запустите Filemon и установите включающий фильтр для «notepad.exe».
2. Откройте Explorer и создайте каталог Test в одном из каталогов NTFS-тома. (B данном примере используется корневой каталог.)
3. Измените разрешения для каталога Test так, чтобы запретить любой вид доступа к нему. He исключено, что вам придется открыть диалоговое окно Advanced Security Settings (Дополнительные параметры безопасности) и задать параметры на вкладке Permissions (Разрешения), чтобы удалить наследуемые разрешения защиты.
 |
Когда вы примените измененные разрешения, Explorer должен будет предупредить вас о том, что никто не получит доступа к этой папке. 4. Запустите Notepad (Блокнот) и введите в нем какой-нибудь текст.
Потом выберите команду Save (Сохранить) из меню FiIe (Файл).
B поле File Name (Имя файла) диалогового окна Save As (Сохранить как) введите c: \test\test.txt (если вы создали папку на томе C:).
5. Notepad выведет следующее сообщение об ошибке.
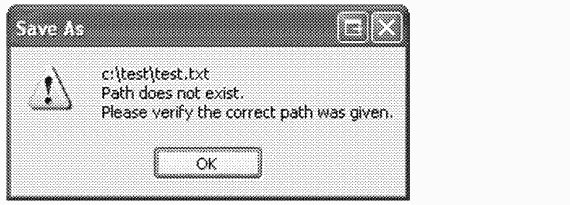 |
6. Это сообщение подразумевает, что каталог C: \Test не существует.
7. B трассировочной информации Filemon вы должны увидеть примерно то же, что и на следующей иллюстрации.
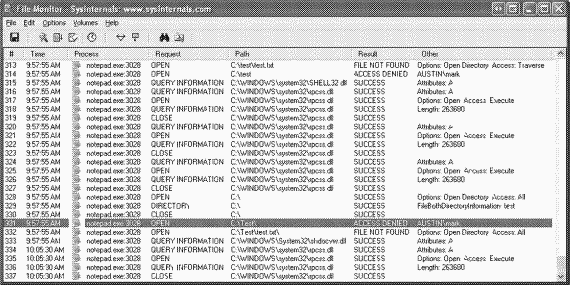 |
Вывод в нижней части иллюстрации был сгенерирован непосредственно перед появлением этого сообщения об ошибке. Строка 331 показывает, что Notepad пытался открыть C: \Test и получил отказ в доступе. Сразу после этого, как видно из строки 332, он попытался открыть каталог C: \Test\Test.txt (на это указывает флаг Directory в столбце Other на той же строке) и получил ошибку «файл не найден», потому что такого каталога нет. Сообщение Notepad «Path does not exist» (Путь не существует) согласуется с последней ошибкой, но не с первой. Поэтому кажется, что Notepad сначала пытался открыть каталог, а когда это не удалось, он почему-то решил, что имя C: \Test\Test.txt соответствует каталогу, а не файлу. He сумев открыть такой каталог, Notepad вывел сообщение об ошибке, но истинной причиной, как показывает Filemon, был отказ в доступе.
Filemon широко применяется Microsoft и другими организациями для решения трудных или почти неуловимых проблем. Рассмотрим один из примеров, где Filemon помог докопаться до истинной причины некорректного сообщения об ошибке, генерируемого службой Windows Installer. Когда пользователь пытался установить программу из ее файла Windows Installer Package, служба Windows Installer сообщала об ошибке, показанной на рис. 12–12; в нем утверждалось, что этой службе не удается записать что-либо в папку Temp. Пользователь убедился, что вопреки этому утверждению каталог, выделенный для временных файлов и заданный в его профиле (эту информацию он получил, набрав в консольном окне команду set temp), находится на томе, где достаточно свободного места, и имеет разрешения по умолчанию.
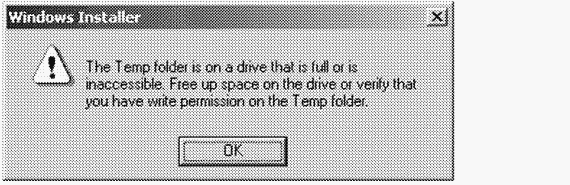 |
Рис. 12–12.
Тогда пользователь запустил Filemon дпя трассировки операций в файловой системе, которые приводят к этой ошибке, и обнаружил ее причину (см. выделенную строку на рис. 12–13). Из этих данных стало ясно, что служба Windows Installer обращалась не к каталогу временных файлов, заданному в профиле пользователя, а к \Windows\Installer. Строка со значением ACCESS DENIED указала на то, что служба Windows Installer выполнялась под учетной записью локальной системы, поэтому пользователь так изменил разрешения на доступ к \Windows\Installer, чтобы учетная запись локальной системы предоставляла права на доступ к этому каталогу дпя записи. Это и решило проблему.
 |
Еще один пример анализа проблем с помощью Filemon. B этом случае пользователь запускал Microsoft Word, и буквально через несколько секунд набора текста окно Word закрывалось без всякого уведомления. Трассировочная информация Filemon, часть которой представлена на рис. 12–14, показала, что перед самым завершением Word повторно считывал одну и ту же часть файла с именем Mssp3es.lex. (Когда процесс завершается, система автоматически закрывает все открытые им описатели. Именно это и отражают строки с номерами от 25460.) Пользователь выяснил, что файлы с расширением. lex относятся к Microsoft Office Proofing Tools, и переустановил этот компонент, после чего проблема исчезла.
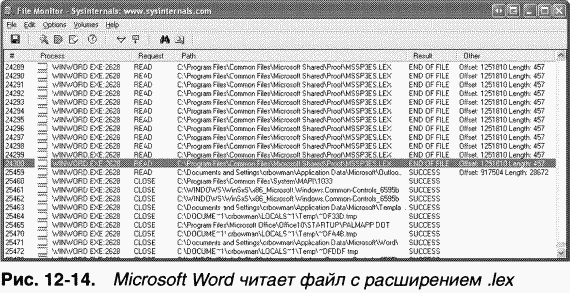 |
B третьем примере при каждом запуске Microsoft Excel выводилось сообщение об ошибке, показанное на рис. 12–15. Из трассировочной информации Filemon на рис. 12–16, полученной в ходе запуска Excel, обнаружилось, что Excel считывает файл 59403e20 из подкаталога Xlstart каталога, в который установлен Microsoft Office. Пользователь изучил документацию на Excel и выяснил, что Excel пытается автоматически открывать любые файлы, хранящиеся в каталоге Xlstart. Однако этот файл не имел никакого отношения к Excel, поэтому открыть его не удавалось и в итоге появлялось сообщение об ошибке. Удаление этого файла устранило проблему.
 |
Рис. 12–15. Сообщение об ошибке при запуске Microsoft Excel
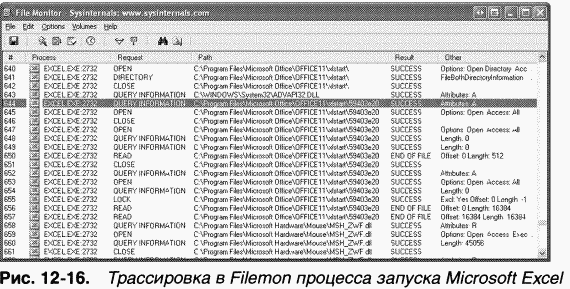 |
Последний пример связан с выявлением устаревших DLL. Пользователь запускал Microsoft Access 2000, и эта программа зависала, как только он пытался импортировать какой-нибудь файл Microsoft Excel. B другой системе с Microsoft Access 2000 тот же файл импортировался успешно. После трассировки операции импорта в обеих системах файлы журналов сравнивались с помощью Windiff. Результаты сравнения представлены на рис. 12–17.
Отбросив незначимые расхождения вроде разных имен временных файлов (строка 19) и разный регистр букв в именах файлов (строка 26), пользователь обнаружил первое существенное различие в результатах трассировки в строке 37. B системе, где импорт заканчивался неудачей, Microsoft Access загружал копию Accwiz.dll из каталога \Winnt\System32, тогда как в системе, где импорт проходил успешно, эта программа считывала Accwiz.dll из \Prog-ra~l\Files\Microsoft\Office. Пользователь изучил копию Accwiz.dll в \Winnt\ System32 и заметил, что она относится к более старой версии Microsoft Access, но порядок поиска DLL в системе приводил к тому, что этот экземпляр обнаруживался первым и до экземпляра нужной версии в каталоге, где установлен Microsoft Access 2000, дело не доходило. Удалив эту копию и зарегистрировав корректную версию, пользователь решил проблему.
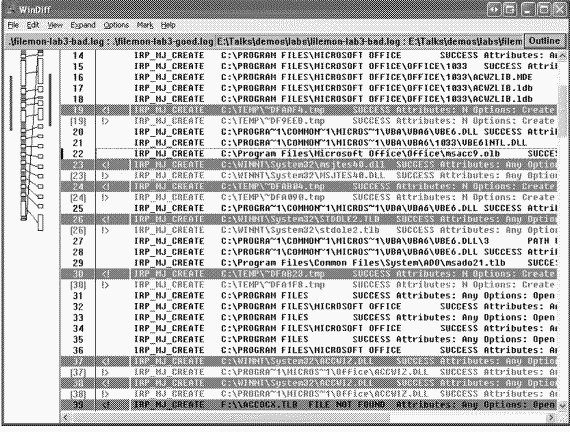 |
Рис. 12–17. Сравнение журналов трассировки Microsoft Access в двух системах
Это лишь некоторые примеры, демонстрирующие, как с помощью Filemon выявлять истинные причины проблем в файловой системе, о которых приложения не всегда сообщают корректно. B остальной части главы мы сосредоточимся на описании «родной» для Windows файловой системы — NTFS.
B следующем разделе мы расскажем о требованиях, определявших разработку NTFS, и о дополнительных возможностях этой файловой системы.
C самого начала разработка NTFS велась с учетом требований, предъявляемых к файловой системе корпоративного класса. Чтобы свести к минимуму потери данных в случае неожиданного выхода системы из строя или ее краха, файловая система должна гарантировать целостность своих метаданных. Дпя защиты конфиденциальных данных от несанкционированного доступа файловая система должна быть построена на интегрированной модели защиты. Наконец, она должна поддерживать защиту пользовательских данных за счет программной избыточности данных в качестве недорогой альтернативы аппаратным решениям. Здесь вы узнаете, как эти возможности реализованы в NTFS.
B соответствии с требованиями к надежности хранения данных и доступа к ним NTFS обеспечивает восстановление файловой системы на основе кон цепции
NTFS использует атомарные транзакции для реализации возможности восстановления файловой системы. Если некая программа инициирует операцию ввода-вывода, которая изменяет структуру NTFS-тома, т. е. модифицирует структуру каталогов, увеличивает длину файла, выделяет место под новый файл и др., то NTFS обрабатывает такую операцию как атомарную транзакцию. NTFS гарантирует, что транзакция будет либо полностью выполнена, либо отменена, если хотя бы одну из операций не удастся завершить из-за сбоя системы. O том, как это делается в NTFS, см. раздел «Поддержка восстановления в NTFS» далее в этой главе.
Кроме того, NTFS использует избыточность для хранения критически важной информации файловой системы, так что, если на диске появится сбойный сектор, она все равно сможет получить доступ к этой информации. Это одна из особенностей NTFS, отличающих ее от FAT и HPFS («родной» файловой системы OS/2).
Защита в NTFS построена на модели объектов Windows. Файлы и каталоги защищены от доступа пользователей, не имеющих соответствующих прав (подробнее о защите в Windows см. главу 8). Открытый файл реализуется в виде объекта «файл» с дескриптором защиты, хранящимся на диске как часть файла. Прежде чем процесс сможет открыть описатель какого-либо объекта, в том числе объекта «файл», система защиты Windows должна убедиться, что у этого процесса есть соответствующие полномочия. Дескриптор защиты в сочетании с требованием регистрации пользователя при входе в систему гарантирует, что ни один процесс не получит доступа к файлу без разрешения системного администратора или владельца файла.
Восстанавливаемость NTFS действительно гарантирует, что файловая система тома останется доступной, но не дает гарантии полного восстановления пользовательских файлов. Последнее возможно за счет поддержки избыточности данных.
Избыточность данных для пользовательских файлов реализуется через многоуровневую модель драйверов Windows (см. главу 9), которая поддерживает отказоустойчивые диски. При записи данных на диск NTFS взаимодействует с диспетчером томов, а тот — с драйвером жесткого диска. Диспетчер томов может
NTFS — это не только восстанавливаемая, защищенная, надежная и эффективная файловая система, способная работать в системах повышенной ответственности. Она поддерживает ряд дополнительных возможностей (некоторые из них доступны приложениям через API-функции, другие являются внутренними):
• множественные потоки данных;
• имена на основе Unicode;
• универсальный механизм индексации;
• динамическое переназначение плохих кластеров;
• жесткие связи и точки соединения;
• сжатие и разреженные файлы;
• протоколирование изменений;
• квоты томов, индивидуальные для каждого пользователя;
• отслеживание ссылок;
• шифрование;
• поддержка POSIX;
• дефрагментация
• поддержка доступа только для чтения.
Обзор этих возможностей приводится в следующих разделах.
B NTFS каждая единица информации, сопоставленная с файлом (имя и владелец файла, метка времени и т. д.), реализована в виде атрибута файла (атрибута объекта NTFS). Каждый атрибут состоит из одного потока данных (stream), т. е. из простой последовательности байтов. Это позволяет легко добавлять к файлу новые атрибуты (и соответственно новые потоки). Поскольку данные являются всего лишь одним из атрибутов файла и поскольку можно добавлять новые атрибуты, файлы и каталоги NTFS могут содержать несколько потоков данных.
B любом файле NTFS по умолчанию имеется один безымянный поток данных. Приложения могут создавать дополнительные, именованные потоки данных и обращаться к ним по именам. Чтобы не изменять Windows-функции API ввода-вывода, которым имя файла передается как строковый аргумент, имена потоков данных задаются через двоеточие (:) после имени файла, например:
Каждый поток имеет свой выделенный размер (объем зарезервированного для него дискового пространства), реальный размер (использованное число байтов) и длину действительных данных (инициализированная часть потока). Кроме того, каждому потоку предоставляется отдельная файловая блокировка, позволяющая блокировать диапазоны байтов и поддерживать параллельный доступ.
Множественные потоки данных использует, например, компонент поддержки файлового сервера Apple Macintosh, поставляемый с Windows Server. Системы Macintosh используют два потока данных в каждом файле: один — для хранения данных, другой — для хранения информации о ресурсах (тип файла, значок, представляющий файл в пользовательском интерфейсе, и т. д.). Поскольку NTFS поддерживает множественные потоки данных, пользователь Macintosh может скопировать целую папку Macintosh на сервер Windows, а другой пользователь Macintosh может скопировать ее с сервера без потери информации о ресурсах.
Windows Explorer — еще одно приложение, использующее такие потоки. Когда вы щелкаете правой кнопкой мыши файл NTFS и выбираете команду Properties, на экране появляется диалоговое окно, вкладка Summary (Сводка) которого позволяет сопоставить с файлом такую информацию, как заголовок, тема, имя автора и ключевые слова. Windows Explorer хранит эту информацию в альтернативном потоке под названием Summary Information, добавляемом к файлу.
Другие приложения тоже могут использовать множественные потоки данных. Например, утилита резервного копирования могла бы с помощью дополнительного потока данных сохранять метки времени, связанные с резервным копированием файлов, а утилита архивирования — реализовать иерархическое хранилище, в котором файлы, созданные ранее заданной даты или не востребованные в течение указанного периода, перемещались бы на ленточные накопители. При этом она могла бы скопировать файл на ленту, установить его поток данных по умолчанию равным 0 и добавить новый поток данных, указывающий название и местонахождение картриджа, в котором хранится файл.
ЭКСПЕРИМЕНТ: просмотр потоков
Большинство приложений Windows не рассчитано на работу с дополнительными именованными потоками, но команды
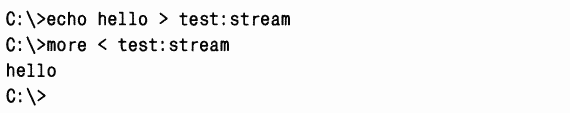 |
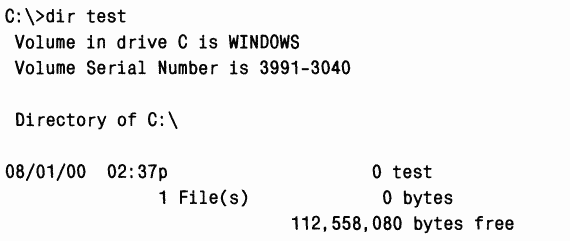
При перечислении содержимого каталога размер файла test не отражает данные, хранящиеся в дополнительном потоке, поскольку в этом случае NTFS возвращает размер только безымянного потока данных.
 |
Утилита Streams (
 |
Как и Windows в целом, NTFS полностью поддерживает Unicode, используя Unicode-символы для хранения имен файлов, каталогов и томов. Unicode, 16-битная кодировка символов, обеспечивает уникальное представление любого символа основных языков мира, что упрощает обмен информацией между странами. Поскольку в Unicode имеется уникальное представление каждого символа, последний не зависит от того, какая кодовая страница загружена в операционную систему. Длина имени каждого каталога или файла в пути может достигать 255 символов; в нем могут быть символы Unicode, пробелы и несколько точек.
Архитектура NTFS позволяет индексировать атрибуты файлов на дисковом томе. Это дает возможность файловой системе вести эффективный поиск файлов по неким критериям, например находить все файлы в определенном каталоге. Файловая система FAT индексирует имена файлов, но не сортирует их, что замедляет просмотр больших каталогов.
Некоторые функции NTFS используют преимущества универсальной индексации, в том числе консолидированных дескрипторов защиты, где дескрипторы защиты файлов и каталогов на томе хранятся в едином внутреннем потоке без дубликатов; при этом они индексируются с использованием внутреннего идентификатора защиты, определяемого NTFS. Об индексации с помощью этих средств см. раздел «Структура NTFS на диске» далее в этой главе.
Обычно, если программа пытается считать данные из плохого сектора диска, операция чтения заканчивается неудачей, а данные соответствующего кластера становятся недоступными. Однако, если диск отформатирован как отказоустойчивый том NTFS, специальный драйвер Windows динамически считывает «хорошую» копию данных, хранившихся в плохом секторе, и посылает NTFS предупреждение о плохом секторе. NTFS выделяет новый кластер, заменяющий тот, в котором находится плохой сектор, и копирует данные в этот кластер. Плохой кластер помечается как аварийный и больше не используется. Восстановление данных и динамическое переназначение плохих кластеров особенно полезно для файловых серверов и отказоустойчивых систем, а также для всех приложений, в которых потеря данных недопустима. Если на момент появления плохого сектора диспетчер томов не был загружен, NTFS все равно заменяет кластер и не допускает его повторного использования, хотя восстановить данные из плохого сектора уже не удастся.
B дополнение к жестким связям NTFS поддерживает другой тип перенаправления —
Точки соединения опираются на механизм NTFS «точки повторного разбора» (см. раздел «Точки повторного разбора» далее в этой главе).
• Владелец тэга повторного разбора может манипулировать полным именем файла, при анализе которого обнаружена точка повторного разбора, и инициировать ввод-вывод по измененному пути. Точки соединения используют этот вариант, например, для перенаправления каталогов.
• Владелец тэга повторного разбора может удалить из файла точку повторного разбора, каким-либо образом изменить файл, а затем инициировать новую операцию файлового ввода-вывода. По такому принципу точки повторного разбора используются системой Hierarchical Storage Management (HSM). HSM архивирует файлы, перемещая их содержимое на ленточные накопители и оставляя вместо содержимого файлов точки повторного разбора. Когда какой-либо процесс обращается к архивированному файлу, драйвер фильтра HSM (\Windows\System32\Drivers\Rsfilter.sys) удаляет из этого файла точку повторного разбора, считывает его данные с архивного носителя и инициирует повторное обращение к файлу. Windows-функций для создания точек повторного разбора нет. Вместо них процессы должны использовать управляющий код FSCTL_SET_REPARSE_ POINT файловой системы в сочетании с Windows-функцией
Процесс может запросить содержимое точки повторного разбора с помощью управляющего кода FSCTL_GET_REPARSE_POINT. B атрибутах файла, сопоставленного с точкой повторного разбора, присутствует флаг FILEAT-TRIBUTE_REPARSE_POINT, что позволяет приложениям проверять наличие точек повторного разбора вызовом Windows-функции
ЭКСПЕРИМЕНТ: создание точки соединения
B Windows нет средств для создания точек соединения, но вы можете создать такую точку с помощью утилиты Junction
NTFS поддерживает сжатие файловых данных. Поскольку NTFS выполняет процедуры сжатия и декомпрессии прозрачно, нет необходимости модифицировать приложения для того, чтобы они могли пользоваться преимуществами этой функции. Каталог также может быть сжат, что влечет за собой сжатие и тех файлов, которые будут впоследствии созданы в этом каталоге.
Приложения сжимают и разархивируют файлы, передавая
Второй тип сжатия известен под названием
Как и в случае сжатых файлов, NTFS прозрачно управляет разреженными файлами. Приложения указывают состояние разреженности файла, передавая
Приложениям многих типов нужно отслеживать изменения файлов и каталогов тома. Например, программа автоматического резервного копирования первоначально выполняет полное резервное копирование, а в дальнейшем копирует только измененные файлы. Очевидный способ мониторинга изменений тома — его сканирование с записью состояния файлов и каталогов и анализ отличий при следующем сканировании. Однако этот процесс может негативно повлиять на производительность системы — особенно на компьютерах, хранящих тысячи и десятки тысяч файлов.
Альтернативный подход для приложения заключается в том, чтобы зарегистрироваться на получение уведомлений об изменении содержимого каталогов. Для этого предназначена Windows-функция
NTFS предусматривает третий подход, в котором преодолены недостатки первых двух: приложение может настроить журнал изменений NTFS с помощью функции
Системным администраторам часто бывает нужно отслеживать или ограничивать дисковое пространство, занимаемое пользователями на общих томах в сети. Поэтому NTFS поддерживает управление дисковым пространством на основе квот, позволяя выделять квоты каждому пользователю. NTFS можно настроить на запись в системный журнал события, возникающего в тот момент, когда пользователь превышает пороговое значение, близкое к лимиту. При попытке пользователя занять больше места, чем разрешает его квота, NTFS также регистрирует соответствующее событие в системном журнале и, кроме того, завершает файловый ввод-вывод приложения, вызвавшего нарушение квоты, с кодом ошибки «disk full» («диск заполнен»).
NTFS отслеживает использование тома благодаря тому факту, что помечает файлы и каталоги идентификаторами защиты (SID) пользователей, создавших эти объекты на томе (определение SID см. в главе 8). Сумма логических размеров файлов и каталогов, принадлежащих пользователю, сравнивается с квотой, определенной администратором. Поэтому пользователь не может превысить свою квоту, создав пустой разреженный файл и потом заполняя его ненулевыми значениями. Кстати, хотя 50-килобайтный файл может быть сжат до 10 Кб, при учете используется его исходный размер — 50 Кб.
По умолчанию отслеживание квот на томах отключено. Чтобы разрешить отслеживание квот, указать пороговые значения для выдачи предупреждений, задать ограничения и настроить реакцию NTFS на достижение одного из этих пороговых значений, используйте вкладку Quota (Квота) окна свойств тома (рис. 12–18). Диалоговое окно Quota Entries (Записи квот), которое можно открыть с этой вкладки, позволяет администратору задавать различные лимиты и поведение NTFS для каждого пользователя. Приложения, которым требуется управление на основе квот NTFS, используют СОМ-интерфейсы квот, в том числе
 |
B пространстве имен оболочки Windows (например, на рабочем столе) можно создавать ярлыки (shortcuts) файлов, находящихся в пространстве имен файловой системы. Такие ярлыки используются, например, в меню Start.
Аналогичным образом OLE-связи позволяют встраивать документы одних приложений в документы, созданные другими приложениями. OLE-связи поддерживаются всеми приложениями из пакета Microsoft Office, включая PowerPoint, Excel и Word.
Хотя OLE-связи дают возможность легко соединять файлы друг с другом и с пространством имен оболочки, управлять ими в прошлом было нелегко. Если пользователь Windows NT 4, Windows 95 или Windows 98 перемещал источник OLE-связи или ярлыка оболочки (источником называется файл или каталог, на который ссылается OLE-связь или ярлык), связь разрывалась, и система предпринимала попытку найти источник связи эвристическим методом. B Windows файловая система NTFS включает поддержку отслеживания распределенных связей (distributed link-tracking), обеспечивающую целостность ярлыков оболочки и OLE-связей при перемещении источников на другой том NTFS в пределах одного домена.
Отслеживание связей в NTFS реализуется на основе необязательного атрибута файла, известного под названием
Корпоративные пользователи часто хранят на своих компьютерах конфиденциальную информацию. Хотя данные на серверах компаний обычно надежно защищены, информация, хранящаяся на портативном компьютере, может попасть в чужие руки в случае потери или кражи компьютера. Права доступа к файлам NTFS в таком случае не защитят данные, поскольку полный доступ к томам NTFS можно получить независимо от их защиты — достаточно воспользоваться программами, умеющими читать файлы NTFS вне среды Windows. Более того, права доступа к файлам NTFS становятся бесполезны при использовании другой системы Windows и учетной записи администратора. Вспомните из главы 8, что учетная запись администратора обладает привилегиями захвата во владение и резервного копирования, любая из которых позволяет получить доступ к любому защищенному объекту в обход его параметров защиты.
NTFS поддерживает механизм Encrypting File System (EFS), с помощью которого пользователи могут шифровать конфиденциальные данные. EFS, как и механизм сжатия файлов, полностью прозрачен для приложений. Это означает, что данные автоматически расшифровываются при чтении их приложением, работающим под учетной записью пользователя, который имеет права на просмотр этих данных, и автоматически шифруются при изменении их авторизованным приложением.
EFS использует криптографические сервисы, предоставляемые Windows в пользовательском режиме, и состоит из драйвера устройства режима ядра, тесно интегрированного с NTFS и DLL-модулями пользовательского режима, которые взаимодействуют с подсистемой локальной аутентификации (LSASS) и криптографическими DLL.
Доступ к зашифрованным файлам можно получить только с помощью закрытого ключа из криптографической пары EFS (которая состоит из закрытого и открытого ключей), а закрытые ключи защищены паролем учетной записи. Таким образом, без пароля учетной записи, авторизованной для просмотра данных, доступ к зашифрованным EFS файлам на потерянных или краденых портативных компьютерах нельзя получить никакими средствами (кроме грубого перебора паролей).
Windows-функции
Как говорилось в главе 2, одно из требований KWindows состояло в том, что она должна полностью поддерживать стандарт POSIX 1003.1. Стандарт POSIX требует от файловой системы поддержки имен файлов и каталогов, чувствительных к регистру букв, цепочечных разрешений (traversal permissions) (для доступа к файлу нужны права на доступ к каждому каталогу на пути к этому файлу), метки времени изменения файла (отличной от метки времени последней модификации файла в MS-DOS) и жестких связей. Вся эта функциональность в NTFS реализована.
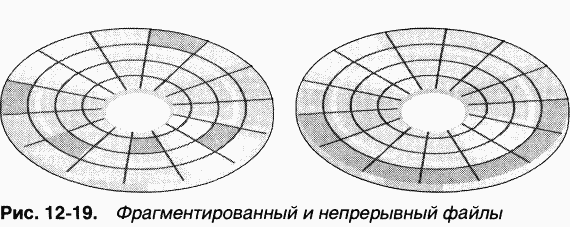
Многие верят в то, что NTFS якобы автоматически оптимизирует размещение файлов на диске, не допуская их фрагментации. Хотя она стремится записывать файлы в непрерывные области, со временем файлы на томе могут стать фрагментированными — особенно когда свободного пространства мало. Файл является фрагментированным, если его данные занимают несмежные кластеры. Так, на рис. 12–19 показан фрагментированный файл, состоящий из трех фрагментов. Ho, как и большинство файловых систем (включая версию FAT в Windows), NTFS не предпринимает специальных мер по поддержанию непрерывного размещения файлов на диске — разве что резервирует область дискового пространства, называемую зоной главной таблицы файлов (master file table, MFT), где и хранится MFT (NTFS разрешает выделять место под файлы из зоны MFT, когда на томе остается мало свободного пространства.) Подробнее о MFT см. раздел «Главная таблица файлов» далее в этой главе.
 |
Для упрощения разработки независимых средств дефрагментации дисков в Windows включен API дефрагментации, с помощью которого подобные утилиты могут перемещать файловые данные так, чтобы файлы занимали непрерывные кластеры. Этот API реализован на основе управляющих кодов файловой системы: FSCTL_GET_VOLUME_BITMAP (возвращает карту свободных и занятых кластеров тома), FSCTL_GET_RETRIEVAL_POINTERS (возвращает карту кластеров, занятых файлом) и FSCTL_MOVE_FILE (перемещает файл).
B Windows имеется встроенная программа дефрагментации, доступная через утилиту Disk Defragmenter (\Windows\System32\Dfrg.msc). Ей присущ ряд ограничений, в частности в Windows 2000 эту утилиту нельзя запускать из командной строки или автоматически запускать по заданному расписанию. B Windows XP и Windows Server 2003 у программы дефрагментации появился интерфейс командной строки, \Windows\System32\Defrag.exe, позволяющий запускать процесс дефрагментации интерактивно или по расписанию, но она по-прежнему не сообщает детальных отчетов и не поддерживает такие возможности, как исключение определенных файлов или каталогов из процесса дефрагментации. Сторонние утилиты дефрагментации дисков, как правило, предлагают более богатую функциональность.
B Windows XP поддержка дефрагментации для NTFS была переписана, чтобы снять часть ограничений, которые были в Windows 2000. Так, в Windows 2000 поддержка дефрагментации NTFS опиралась на диспетчер кэша, что создавало ряд ограничений, например невозможность перемещения файловых блоков размером более 256 Кб или дефрагментации файлов метаданных NTFS. (Заметьте, что 256 Кб — это размер представлений, поддерживаемых диспетчером кэша. Подробнее о диспетчере кэша см. главу 11.) B реализации дефрагментации NTFS в Windows XP и Windows Server 2003 существует лишь одно ограничение — нельзя дефрагментировать страничные файлы и файлы журналов NTFS.
До Windows XP драйвер файловой системы NTFS поддерживал монтирование тома исключительно на записываемом носителе, куда он должен был помещать файлы журналов транзакций. Драйверы NTFS в Windows XP и Windows Server 2003 могут монтировать тома на носителях только для чтения; эта функциональность нужна во встраиваемых системах, в которых базовые образы файловой системы (base file system images) доступны только для чтения.
Как отмечалось в главе 9, подсистема ввода-вывода Windows устроена так, что NTFS и другие файловые системы представляют собой загружаемые драйверы устройств режима ядра. Они неявно вызываются приложениями, использующими Windows или другие API ввода-вывода (например, POSIX). Как показано на рис. 12–20, подсистемы окружения вызывают системные сервисы, которые в свою очередь находят соответствующие загруженные драйверы и вызывают их. (O диспетчеризации системных сервисов см. раздел «Диспетчеризация системных сервисов» главы 3.)
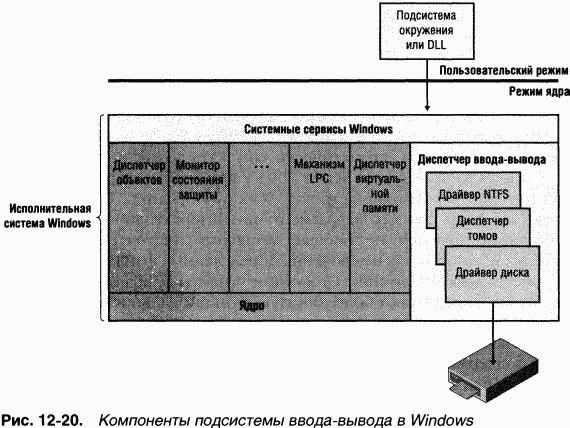 |
Драйверы передают друг другу запросы ввода-вывода, вызывая диспетчер ввода-вывода исполнительной системы. Использование диспетчера ввода-вывода в качестве промежуточного звена обеспечивает независимость каждого драйвера, что позволяет загружать и выгружать его без последствий для других драйверов. Кроме того, драйвер NTFS взаимодействует с тремя другими компонентами исполнительной системы (рис. 12–21), тесно связанными с файловыми системами.
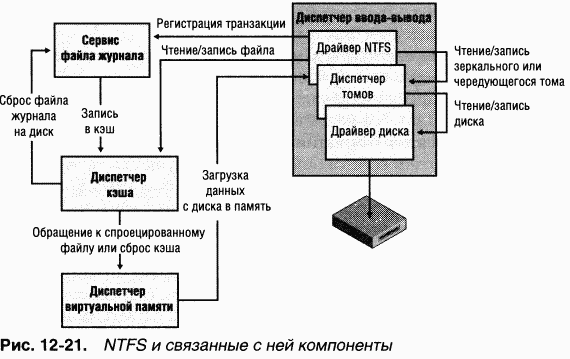 |
Сервис файла журнала (log file service, LFS) является частью NTFS и предоставляет функции для поддержки журнала изменений на диске. Файл журнала LFS используется при восстановлении тома NTFS в случае аварии системы (подробнее о LFS см. раздел «Сервис файла журнала» далее в этой главе).
Диспетчер кэша — компонент исполнительной системы, предоставляющий общесистемные сервисы кэширования для NTFS и драйверов других файловых систем, в том числе сетевых (т. е. для серверов и редиректоров). Все файловые системы, реализованные в Windows, получают доступ к кэшированным файлам, проецируя их на системное адресное пространство, а затем считывая соответствующие участки виртуальной памяти. C этой целью диспетчер кэша предоставляет диспетчеру памяти специализированный интерфейс файловых систем. Когда программа пытается обратиться к какой-либо части файла, не загруженной в кэш (промах кэша), диспетчер памяти вызывает NTFS для обращения к драйверу диска и загрузки нужных файловых данных. Диспетчер кэша оптимизирует дисковый ввод-вывод, вызывая диспетчер памяти (для сброса на диск содержимого кэша в фоновом режиме) из потоков подсистемы отложенной записи.
NTFS участвует в модели объектов Windows, реализуя файлы в виде объектов. Такая реализация допускает совместное использование файлов и их защиту диспетчером объектов, который управляет всеми объектами уровня исполнительной системы (о диспетчере объектов см. главу 3).
Приложение создает файлы и обращается к ним так же, как и к любым другим объектам Windows, — через описатели объектов. K тому времени, когда запрос ввода-вывода достигает NTFS, диспетчер объектов и система защиты уже убедились в наличии у вызывающего процесса прав на запрошенные им виды доступа к объекту «файл». Система защиты сравнила маркер доступа вызывающего процесса с элементами ACL этого объекта «файл» (подробнее об ACL см. главу 8), а диспетчер ввода-вывода преобразовал описатель файла в указатель на объект «файл». NTFS использует информацию из объекта «файл» для обращения к файлу на диске.
Ha рис. 12–22 показаны структуры данных, связывающие описатель файла со структурой файловой системы на диске.
NTFS получает адрес файла на диске из объекта «файл» по нескольким указателям. Как видно из рис. 12–22, объект «файл», представляющий один вызов системного сервиса для открытия файла, указывает на
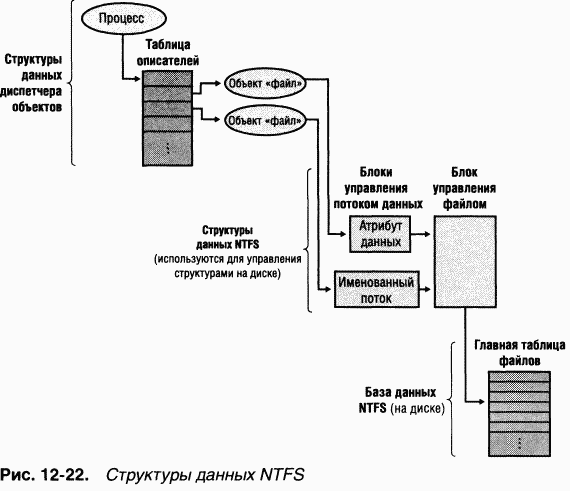 |
Здесь мы рассмотрим структуру тома NTFS, включая способы разбиения дискового пространства и его организации в кластеры, принципы хранения на диске реальных файловых данных и информации об атрибутах, а также поясним, как работает механизм сжатия данных в NTFS.
Структура NTFS начинается с тома.
Ha диске может быть один или несколько томов. NTFS обрабатывает каждый том независимо от других. Три примера конфигурации 150-мегабайтного жесткого диска показаны на рис. 12–23.
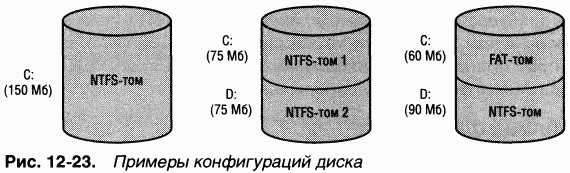 |
Том состоит из набора файлов и свободного пространства, оставшегося в данном разделе диска. B FAT том также содержит области, специально отформатированные для использования файловой системой. Ho в томе NTFS все данные файловой системы вроде битовых карт, каталогов и даже начального загрузочного кода хранятся как обычные файлы.
Размер кластера на томе NTFS, или
Внутренне NTFS работает только с кластерами. (Однако NTFS инициирует низкоуровневые операции ввода-вывода на томе, выравнивая передаваемые данные по размеру сектора и подгоняя их объем под значение, кратное размеру секторов.) NTFS использует кластер как единицу выделения пространства для поддержания независимости от размера физического сектора. Это позволяет NTFS эффективно работать с очень большими дисками, используя кластеры большего размера, и поддерживать нестандартные диски с размером секторов, отличным от 512 байтов. Применение больших кластеров на больших томах уменьшает фрагментацию и ускоряет выделение свободного пространства за счет небольшого проигрыша в эффективности использования дискового пространства. Команда
NTFS адресуется к конкретным местам на диске, используя
B NTFS все данные, хранящиеся на томе, содержатся в файлах. Это относится и к структурам данных, используемым для поиска и выборки файлов, к начальному загрузочному коду и битовой карте, в которой регистрируется состояние пространства всего тома (метаданные NTFS). Хранение всех видов данных в файлах позволяет файловой системе легко находить и поддерживать данные, а каждый файл может быть защищен дескриптором защиты. Кроме того, при появлении плохих секторов на диске, NTFS может переместить файлы метаданных.
Главная таблица файлов (MFT) занимает центральное место в структуре NTFS-тома. MFT реализована как массив записей о файлах. Размер каждой записи фиксирован и равен 1 Кб (см. раздел «Записи о файлах» далее в этой главе). Логически MFT содержит по одной строке на каждый файл тома, включая строку для самой MFT Кроме MFT, на каждом томе NTFS имеется набор файлов метаданных с информацией, необходимой для реализации структуры файловой системы. Имена всех файлов метаданных NTFS начинаются со знака доллара ($), хотя эти знаки скрыты. Так, имя файла MFT — $Mft. Остальные файлы NTFS-тома являются обычными файлами и каталогами (рис. 12–24).
 |
Обычно каждая запись MFT соответствует отдельному файлу Ho если у файла много атрибутов или он сильно фрагментирован, для него может понадобиться более одной записи. Тогда первая запись MFT, хранящая адреса других записей, называется
ЭКСПЕРИМЕНТ: просмотр MFT
Утилита Nfi из OEM Support Tools (входит в отладочные средства Windows; ее можно скачать с
 |
 |
 |
 |
При первом обращении к тому NTFS должна смонтировать его, т. е. считать с диска метаданные и сформировать внутренние структуры данных, необходимые для обработки обращений к файловой системе. Чтобы смонтировать том, NTFS ищет в загрузочном секторе физический адрес MFT на диске. Запись о самой MFT является первым элементом в этой таблице, вторая запись указывает на файл в середине диска ($MftMirr), который называется зеркальной копией MFT и содержит копию первых нескольких записей MFT Если по каким-либо причинам считать часть MFT не удастся, для поиска файлов метаданных будет использована именно эта копия MFT.
Найдя запись для MFT, NTFS получает из ее атрибута данных информацию о сопоставлении VCN и LCN и сохраняет ее в памяти. B каждой группе (run) хранится сопоставление VCN-LCN и длина этой группы — вот и вся информация, необходимая для того, чтобы найти LCN по VCN. Эта информация сообщает NTFS, где на диске искать группы, образующие MFT (O группах см. раздел «Резидентные и нерезидентные атрибуты» далее в этой главе.) Затем NTFS обрабатывает записи MFT еще для нескольких файлов метаданных и открывает эти файлы. Наконец, NTFS выполняет операцию восстановления фаршовой системы (см. раздел «Восстановление» далее в этой главе) и открывает остальные файлы метаданных. C этого момента пользователь может обращаться к данному дисковому тому.
B процессе работы системы NTFS ведет запись в другой важный файл метаданных —
Еще один элемент MFT зарезервирован для корневого каталога (также обозначаемого как «\»). Его запись содержит индекс файлов и каталогов, хранящихся в корне структуры каталогов NTFS. Когда NTFS впервые получает запрос на открытие файла, она начинает его поиск с записи корневого каталога. Открыв файл, NTFS сохраняет файловую ссылку MFT для этого файла и поэтому в следующий раз, когда понадобится считать или записать тот же файл, сможет напрямую обратиться к его записи в MFT.
NTFS регистрирует распределение дискового пространства в
Другой системный файл,
NTFS поддерживает
Некоторые файлы метаданных NTFS хранит в каталоге расширенных метаданных $Extend, в том числе помещая туда
ЭКСПЕРИМЕНТ: просмотр информации NTFS
Для просмотра информации о NTFS-томе, в том числе о размещении и размере MFT и зоны MFT, вы можете использовать в Windows 2000 утилиту NTFSInfo (с сайта
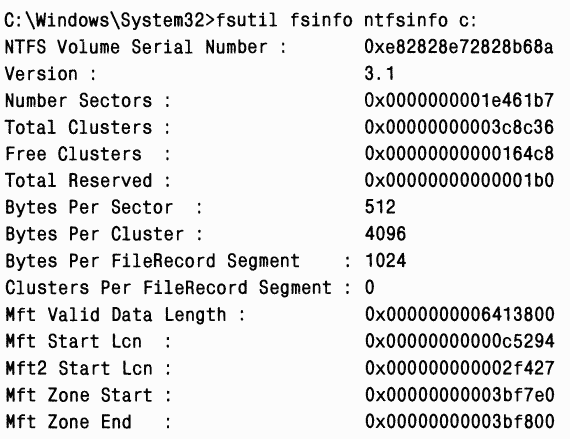 |
Файл на томе NTFS идентифицируется 64-битным значением, которое называется
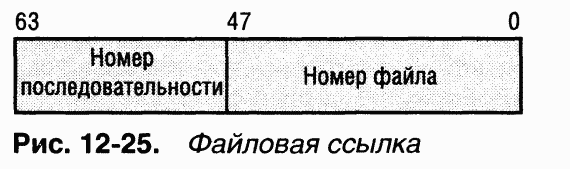 |
NTFS рассматривает файл не просто как хранилище текстовых или двоичных данных, а как совокупность пар атрибутов и их значений, одна из которых содержит данные файла (соответствующий атрибут называется
метку времени и, возможно, дополнительные именованные атрибуты данных. Запись МFТ для небольшого файла показана на рис. 12–26.
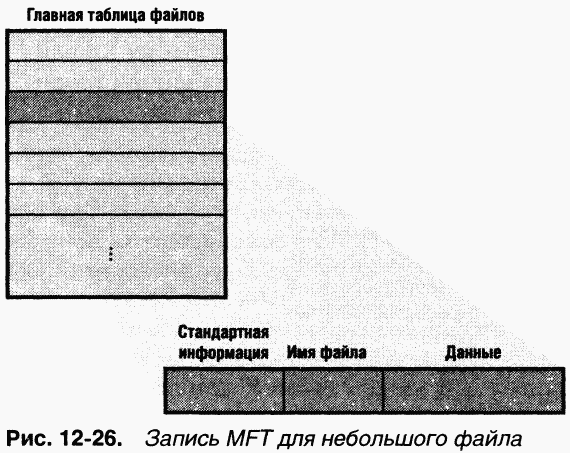 |
Каждый атрибут файла хранится в файле как отдельный поток байтов. Строго говоря, NTFS читает и записывает не файлы, а потоки атрибутов. NTFS поддерживает следующие операции над атрибутами: создание, удаление, чтение (как диапазон байтов) и запись (как диапазон байтов). Сервисы чтения и записи обычно имеют дело с неименованным атрибутом данных. Однако вызывающая программа может указать другой атрибут данных, используя синтаксис именованных потоков данных.
B таблице 12-4 перечислены атрибуты для файлов на томах NTFS (не у каждого файла есть все эти атрибуты).
 |
 |
B таблице 12-4 даны имена атрибутов, но на самом деле атрибуты соответствуют числовым кодам типов, используемым NTFS для упорядочения атрибутов в записи о файле. Файловые атрибуты в записи MFT размещаются в порядке возрастания числовых значений этих кодов. Некоторые типы атрибутов встречаются в записи дважды — например, если у файла несколько атрибутов данных или несколько имен.
Каждый атрибут в записи о файле идентифицируется кодом типа атрибута, имеет значение и необязательное имя. Значение атрибута представляет собой байтовый поток. Так, значением атрибута $FILENAME является имя файла, значением атрибута $DATA — произвольный набор байтов, сохраненный пользователем в файле.
У большинства атрибутов нет имен, хотя у $DATA и атрибутов, связанных с индексом, они обычно есть. Имена позволяют различать атрибуты файла, относящиеся к одному типу. Например, в файле с именованным потоком данных есть два атрибута $DATA: неименованный атрибут $DATA, хранящий неименованный по умолчанию поток данных, и именованный атрибут $DATA с именем дополнительного потока данных.
NTFS и FAT допускают длину каждого имени файла в пути до 255 символов. Эти имена могут содержать Unicode-символы, точки и пробелы. Однако длина имен файлов в FAT, встроенной в MS-DOS, ограничена 8 символами (не-Unicode), за которыми следует расширение из трех символов, отделенное точкой. Рис. 12–27 иллюстрирует различные пространства имен файлов, поддерживаемые Windows, и показывает, как они перекрываются.
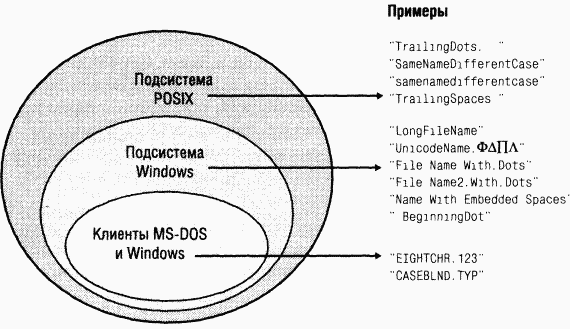 |
Рис. 12–27. Пространства имен файлов, поддерживаемые Windows
POSIX требует самого большого пространства имен из всех подсистем, поддерживаемых Windows. Поэтому пространство имен NTFS эквивалентно пространству имен POSIX. Подсистема POSIX может создавать имена, невидимые приложениям Windows и MS-DOS, в том числе имена с концевыми точками и концевыми пробелами. Создание файла в большом пространстве имен POSIX обычно не является проблемой, потому что вы создаете такой файл для использования подсистемой POSIX или ее клиентской системой.
Ho взаимосвязь между 32-разрядными Windows-приложениями и программами MS-DOS и 16-разрядной Windows намного теснее. Область, отведенная Windows на рис. 12–26, представляет имена файлов, которые подсистема Windows может создавать на томе NTFS, хотя такие имена невидимы программам MS-DOS и 16-разрядной Windows. B эту группу входят имена файлов, не соответствующие формату «8.3» (длинные имена, имена с Unicode-символами, с несколькими точками или начинающиеся с точки, а также имена с внутренними пробелами). При создании файла с таким именем NTFS автоматически генерирует для него альтернативное имя в стиле MS-DOS. Windows показывает такие имена при использовании команды
Имена MS-DOS — полнофункциональные псевдонимы файлов NTFS и хранятся в том же каталоге, что и длинные имена. Ha рис. 12–28 показана запись MFT для файла с автоматически сгенерированным MS-DOS-именем.
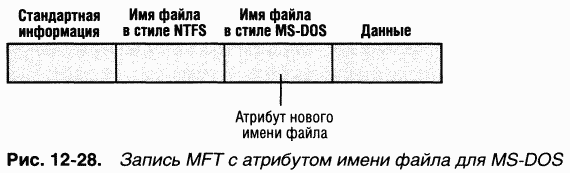 |
Имя NTFS и сгенерированное имя MS-DOS хранятся в той же записи и относятся к одному и тому же файлу. Имя MS-DOS можно использовать для открытия, чтения, записи и копирования файла. Если пользователь переименовывает файл, заменяя длинное имя на краткое или наоборот, новое имя заменяет оба существовавших варианта. Если новое имя является недопустимым для MS-DOS, NTFS генерирует для файла другое MS-DOS-имя.
Вот алгоритм, применяемый NTFS при генерации краткого MS-DOS-имени из длинного.
1. Удалить из длинного имени все символы, недопустимые в именах MS-DOS, включая пробелы и Unicode-символы. Удалить начальную и концевую точки, а также все внутренние точки, кроме последней.
2. Урезать часть строки перед точкой (если она есть) до шести символов и добавить строку «~n» (где
3. Преобразовать полученный набор символов в верхний регистр. MS-DOS нечувствительна к регистру букв в именах файлов, но эта операция гарантирует, что NTFS не сгенерирует для файла новое имя, отличающееся от старого лишь регистром.
4. Если сгенерированное имя дублирует уже имеющееся в каталоге, увеличить порядковый номер в строке «~n» на 1 (или на большее значение).
B таблице 12-5 показаны длинные имена файлов с рис. 12–26 и их MS-DOS-версии, сгенерированные NTFS. Приведенный выше алгоритм и примеры на рис. 12–26 должны дать вам представление об именах в стиле MS-DOS, генерируемых NTFS.
 |
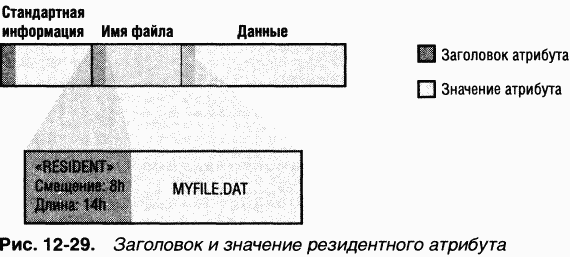
Если файл невелик, все его атрибуты и их значения (например, файловые данные) умещаются в одной записи файла. Когда значение атрибута хранится непосредственно в MFT, атрибут называется
Каждый атрибут начинается со стандартного заголовка, в котором содержится информация об атрибуте, используемая NTFS для базового управления атрибутами. B заголовке, который всегда является резидентным, регистрируется, резидентно ли значение данного атрибута. B случае резидентных атрибутов заголовок также содержит смещение значения атрибута от начала заголовка и длину этого значения (рис. 12–29).
 |
Когда значение атрибута хранится непосредственно в MFT, обращение к нему занимает значительно меньше времени. Вместо того чтобы искать файл в таблице, а затем считывать цепочку кластеров для поиска файловых данных (как, например, поступает FAT), NTFS обращается к диску только один раз и немедленно считывает данные.
Как видно из рис. 12–30, атрибуты небольшого каталога, а также небольшого файла, могут быть резидентными в MFT Для небольшого каталога атрибут «корень индекса» содержит индекс файловых ссылок на файлы и подкаталоги этого каталога.
 |
Конечно, многие файлы и каталоги нельзя втиснуть в запись MFT с фиксированным размером в 1 Кб. Если некий атрибут, например файловые данные, слишком велик и не умещается в записи MFT, NTFS выделяет для него отдельные кластеры за пределами MFT Эта область называется
B случае нерезидентного атрибута (им может быть атрибут данных большого файла) в его заголовке содержится информация, нужная NTFS для поиска значения атрибута на диске. Ha рис. 12–31 показан нерезидентный атрибут данных, хранящийся в двух группах.
 |
Рис. 12–31. Запись в МFТ для большого файла с двумя группами данных
Среди стандартных атрибутов нерезидентными бывают лишь те, чей размер может увеличиваться. Для файлов такими атрибутами являются данные и список атрибутов (не показанный на рис. 12–31). Атрибуты «стандартная информация» и «имя файла» всегда резидентны.
B большом каталоге также могут быть нерезидентные атрибуты (или части атрибутов), как видно из рис. 12–32. B этом примере в записи MFT не хватает места для хранения индекса файлов, составляющих этот большой каталог. Часть индекса хранится в атрибуте корня индекса, а остальное — в нерезидентных группах, называемых
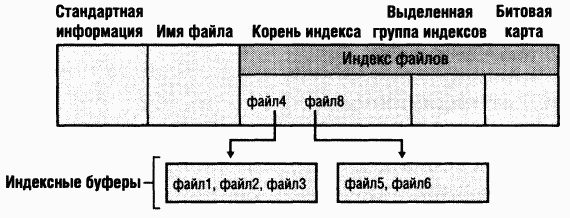 |
Рис. 12–32. Запись MFT для большого каталога с нерезидентным индексом имен файлов
Когда атрибуты файла (или каталога) не умещаются в записи MFT и для них требуется отдельное место, NTFS отслеживает выделяемые группы посредством пар сопоставлений VCN-LCN. LCN представляют последовательность кластеров на всем томе, пронумерованных от 0 до
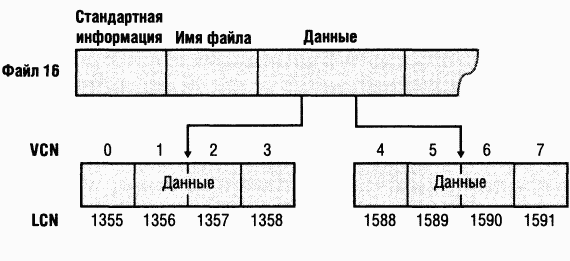 |
Рис. 12–33. VCN для нерезидентного атрибута данных
Если бы этот файл занимал больше двух групп, нумерация в третьей группе началась бы с VCN 8. Как показано на рис. 12–34, заголовок атрибута данных содержит сопоставления VCN-LCN для обоих групп, что позволяет NTFS легко находить выделенные под них области на диске.
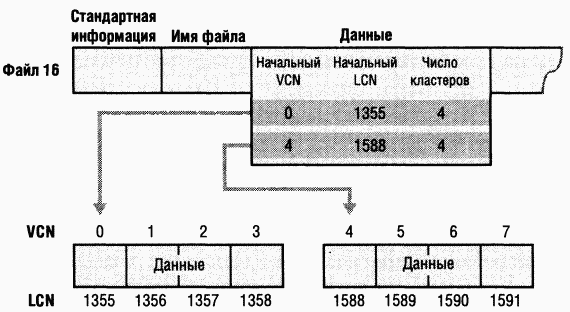 |
Рис. 12–34. Сопоставления VCN-LCN для нерезидентного атрибута данных
Хотя на рис. 12–33 показаны только группы данных, в группах могут храниться и другие атрибуты, если они не умещаются в записи MFT Когда у файла так много атрибутов, что они не умещаются в записи MFT, для хранения дополнительных атрибутов (или заголовков в случае нерезидентных атрибутов) используется вторая запись MFT При этом добавляется атрибут, называемый
NTFS поддерживает сжатие по отдельным файлам, по каталогам и по томам (NTFS сжимает только пользовательские данные, не трогая метаданные файловой системы). Выяснить, сжат ли том, можно через Windows-функцию
Следующий раздел является введением в сжатие данных в NTFS на примере простого случая компрессии разреженных данных. После него мы обсудим сжатие обычных и разреженных файлов.
 |
Данный файл хранится в трех группах, каждая по 4 кластера, и таким образом занимает 12 кластеров. Запись MFT для этого файла представлена на рис. 12–36. Как мы уже отмечали, для экономии места на диске атрибут данных в записи MFT содержит только одно сопоставление VCN-LCN для каждой группы, а не для каждого кластера. Тем не менее каждому VCN от 0 до 11 сопоставлен свой LCN. Первый элемент начинается с VCN 0 и охватывает 4 кластера, второй начинается с VCN 4, также охватывая 4 кластера, и т. д. Такой формат типичен для несжатого файла.
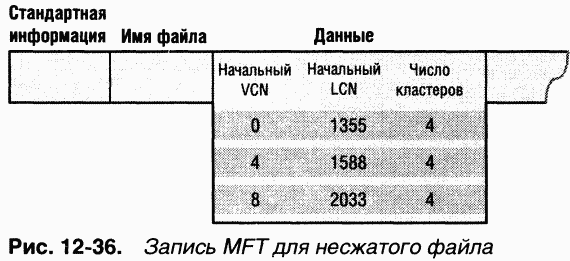 |
Один из способов сжатия файла, применяемых NTFS, состоит в удалении из него длинных цепочек нулей. Если файл разрежен, он обычно сжимается до размера, составляющего лишь часть дискового пространства, необходимого для его хранения в нормальном виде. При последующей записи в этот файл NTFS выделяет пространство только для групп с ненулевыми данными.
Ha рис. 12–37 изображены группы сжатого разреженного файла. Обратите внимание на то, что для некоторых диапазонов VCN файла (16–31 и 64-127) дисковое пространство не выделено.
 |
B записи MFT для этого сжатого файла пропущены блоки VCN кластеров, содержащих нули, т. е. для них не выделено дисковое пространство. Так, первый элемент данных на рис. 12–38 начинается с VCN 0 и охватывает 16 кластеров. Второй элемент перескакивает на VCN 32 и охватывает еще 16 кластеров.
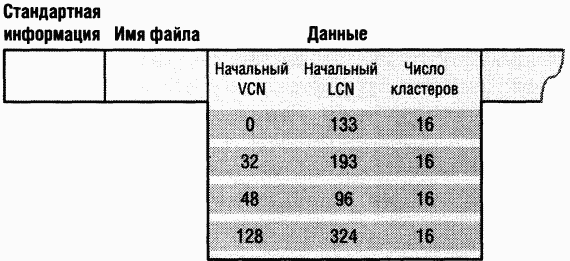 |
Рис. 12–38. Запись MFT дпя сжатого файла, содержащего разреженные данные
Когда программа читает данные из сжатого файла, NTFS проверяет запись MFT, чтобы выяснить, имеется ли сопоставление VCN-LCN для считываемого участка файла. Если программа обращается в невыделенную «дыру» в файле, значит, данные этой части файла состоят из нулей, и тогда NTFS возвращает нули, не обращаясь к диску. Если программа записывает в «дыру» ненулевые данные, NTFS автоматически выделяет дисковое пространство и записывает туда эти данные. Такой метод очень эффективен для разреженных файлов, содержащих много нулевых данных.
Предыдущий пример сжатия разреженного файла довольно надуманный. Он описывает «сжатие» в том случае, когда целые области файла заполнены нулями, но на остальные файловые данные сжатие не оказывает никакого влияния. B большинстве файлов данные не являются разреженными, тем не менее их можно компрессировать по какому-нибудь алгоритму сжатия.
B NTFS пользователи могут сжимать отдельные файлы или все файлы в каталоге. (Новые файлы, создаваемые в сжатом каталоге, сжимаются автоматически. Файлы, существовавшие в каталоге до его сжатия, должны быть сжаты индивидуально.) Сжимая файл, NTFS разбивает его необработанные данные на
 |
При записи данных в сжатый файл NTFS гарантирует, что каждая группа будет начинаться на виртуальной 16-кластерной границе. Таким образом, начальный VCN каждой группы кратен 16, и длина группы не превышает 16 кластеров. При работе со сжатым файлом NTFS единовременно считывает и записывает минимум одну единицу сжатия. Ho при записи сжатых данных NTFS пытается помещать единицы сжатия в физически смежные области, так чтобы их можно было считывать в ходе одной операции ввода-вывода. Размер единицы сжатия в 16 кластеров выбран для уменьшения внутренней фрагментации: чем больше размер единицы сжатия, тем меньше дискового пространства нужно для хранения данных. Размер единицы сжатия, равный l6 кластерам, основан на компромиссе между минимизацией размера сжатых файлов и замедлением операций чтения для программ, использующих прямой (произвольный) доступ к содержимому файлов. При каждом промахе кэша приходится декомпрессировать эквивалент l6 кластеров (вероятность промаха кэша при прямом доступе к файлу выше, чем при последовательном). Ha рис. 12–40 представлена запись MFT для сжатого файла, показанного на рис. 12–39.
Одно из различий между этим сжатым файлом и сжатым разреженным файлом из более раннего примера в том, что в данном случае три группы имеют длину менее 16 кластеров. Считывание этой информации из записи MFT позволяет NTFS определить, сжаты ли данные в этом файле. Каждая группа короче l6 кластеров содержит сжатые данные, которые NTFS должна разархивировать при первом чтении группы в кэш. Группа, длина которой равна точно 16 кластерам, не содержит сжатых данных, а значит, не требует декомпрессии.
 |
Если группа содержит сжатые данные, NTFS разархивирует их во временный буфер и копирует в буфер вызывающей программы. Кроме того, NTFS помещает декомпрессированные данные в кэш, поэтому последующее чтение из этой группы выполняется так же быстро, как и простое чтение из кэша. Все изменения файла NTFS записывает в кэш, позволяя подсистеме отложенной записи асинхронно сжимать и записывать измененные данные на диск. Такая стратегия гарантирует, что запись в сжатый фарш вызовет примерно ту же задержку, что и запись в несжатый файл.
NTFS размещает сжатый файл на диске по возможности в смежных областях. Как указывают LCN, первые две группы сжатого файла на рис. 12–38 являются физически смежными, равно как и две последних. Если две и более группы расположены последовательно, NTFS выполняет опережающее чтение с диска — как и в случае обычных файлов. Поскольку чтение и декомпрессия непрерывных файловых данных выполняются асинхронно и еще до того, как программа запросит эти данные, то в последующих операциях чтения информация извлекается непосредственно из кэша, что значительно ускоряет процесс чтения.
Разреженные файлы (тип файлов NTFS отличающийся от ранее описанных файлов, которые содержат разреженные данные) по сути являются сжатыми файлами, неразреженные данные которых NTFS не сжимает. Однако NTFS обрабатывает данные группы из записи MFT разреженного файла так же, как и в случае сжатых файлов, состоящих из разреженных и неразреженных данных.
Файл журнала изменений, \$Extend\$UsnJrnl, является разреженным файлом, который NTFS создает, только когда приложение активизирует регистрацию изменений. Журнал хранит записи изменений в потоке данных $J. Эти записи включают следующую информацию об изменениях файлов или каталогов:
• время изменения;
• тип изменения (удаление, переименование, увеличение размера и т. д.);
• атрибуты файла или каталога; • имя файла или каталога;
• номер файловой ссылки файла или каталога;
• номер файловой ссылки родительского каталога файла.
Поскольку журнал является разреженным, он никогда не переполняется; когда его размер на диске достигает определенного максимума, NTFS начинает просто обнулять файловые данные, предшествующие текущему блоку информации об изменениях, как показано на рис. 12–41. Ho, чтобы предотвратить постоянное изменение размера журнала, NTFS уменьшает его, только когда он в два раза превосходит установленный максимум.
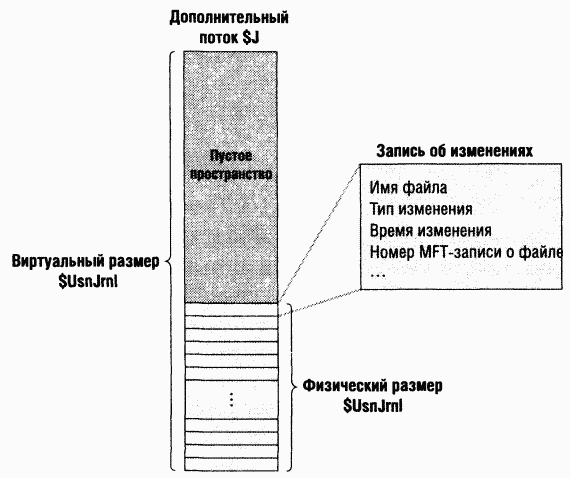 |
Рис. 12–41. Выделение пространства для журнала изменений ($UsnJrnl)
B NTFS каталог — это просто индекс имен файлов, т. е. совокупность имен файлов (с соответствующими файловыми ссылками), организованная таким образом, чтобы обеспечить быстрый доступ. Для создания каталога NTFS индексирует атрибуты «имя файла» из этого каталога. Запись MFT для корневого каталога тома показана на рис. 12–42.
C концептуальной точки зрения, элемент MFT для каталога содержит в своем атрибуте «корень индекса» отсортированный список файлов каталога. Ho для больших каталогов имена файлов на самом деле хранятся в индексных буферах размером по 4 Кб, которые содержат и структурируют имена файлов. Индексные буферы реализуют структуру данных типа «b+ tree», которая позволяет свести к минимуму число обращений к диску при поиске какого-либо файла, особенно в больших каталогах. Атрибут «корень индекса» содержит первый уровень структуры b+ tree (подкаталоги корневого каталога) и указывает на индексные буферы, содержащие следующий уровень (другие подкаталоги или файлы).
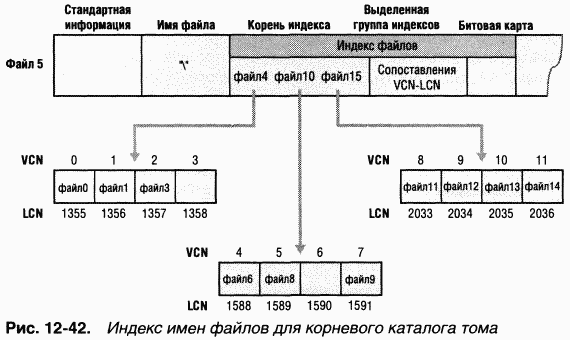 |
Ha рис. 12–42 в атрибуте «корень индекса» и индексных буферах показаны только имена файлов (например,
Атрибут «выделенная группа индексов» сопоставляет VCN групп индексных буферов с LCN, которые указывают, в каком месте диска находятся индексные буферы, а битовая карта используется для учета того, какие VCN в индексных буферах заняты, а какие свободны. Ha рис. 12–42 на каждый VCN, т. е. на каждый кластер, приходится по одной записи для файла, но на самом деле кластер содержит несколько записей. Каждый индексный буфер размером 4 Кб может содержать 20–30 записей для имен файлов.
Структура данных b+ tree — это разновидность сбалансированного дерева, идеальная для организации отсортированных данных, хранящихся на диске, так как позволяет минимизировать количество обращений к диску при поиске заданного элемента. B MFT атрибут корня индекса для каталога содержит несколько имен файлов, выступающих в качестве индексов для второго уровня b+ tree. C каждым именем файла в атрибуте корня индекса связан необязательный указатель индексного буфера. Этот индексный буфер содержит имена файлов, которые с точки зрения лексикографии меньше данного имени. Например, на рис. 12–42
Хранение имен файлов в структурах вида b+ tree дает несколько преимуществ. Поиск в каталоге выполняется быстрее, так как имена файлов хранятся в отсортированном порядке. A когда высокоуровневое программное обеспечение перечисляет файлы в каталоге, NTFS возвращает уже отсортированные имена. Наконец, поскольку b+ tree имеет тенденцию к росту в ширину, а не в глубину, скорость поиска не уменьшается с увеличением размера каталога.
Кроме индексации имен, NTFS обеспечивает универсальную индексацию данных, и некоторая функциональность NTFS (в том числе идентификации объектов, отслеживания квот и консолидированной защиты) использует индексацию для управления внутренними данными.
Кроме идентификатора объекта, назначенного файлу или каталогу и хранящегося в атрибуте $OBJECT_ID записи MFT, NTFS также запоминает соответствие между идентификаторами объектов и номерами их файловых ссылок в индексе Ю файла метаданных \$Extend\$ObjId. Элементы индекса сортируются по значениям идентификатора объекта, благодаря чему NTFS может быстро находить файл по его идентификатору. Таким образом, используя недокументированную функциональность, приложения могут открывать файл или каталог по идентификатору объекта. Ha рис. 12–43 показана взаимосвязь между файлом метаданных $Objid и атрибутами $OBJECT_ID в MFT-записях.
 |
NTFS хранит информацию о квотах в файле метаданных \$Extend\$Quota, который состоит из индексов
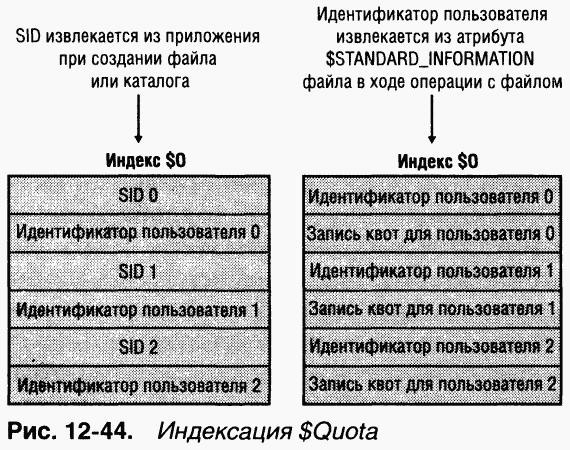 |
Когда приложение создает файл или каталог, NTFS получает SID пользователя этого приложения и ищет соответствующий идентификатор пользователя в индексе $O. Этот идентификатор записывается в атрибут $STANDARD_INFORMATION нового файла или каталога. Затем NTFS просматривает запись квот в индексе $Q и определяет, не превышает ли выделенное дисковое пространство установленные для данного пользователя лимиты. Когда новое дисковое пространство, выделяемое пользователю, превышает пороговое значение, NTFS предпринимает соответствующие меры, например, записывает событие в журнал System (Система) или отклоняет запрос на создание файла или каталога.
NTFS всегда поддерживала средства защиты, которые позволяют администратору указывать, какие пользователи могут обращаться к определенным файлам и каталогам, а какие — не могут. B версиях NTFS до Windows 2000 каждый файл и каталог хранит дескриптор защиты в своем атрибуте защиты. Ho в большинстве случаев администратор применяет одинаковые пара метры защиты к целому дереву каталогов, что приводит к дублированию дескрипторов защиты во всех файлах и подкаталогах этого дерева каталогов. B многопользовательских средах, например в Windows 2000 Server со службой Terminal Services, такое дублирование может потребовать слишком большого пространства на диске, поскольку дескрипторы защиты будут содержать элементы для множества учетных записей. NTFS в Windows 2000 и более поздних версиях OC оптимизируют использование дискового пространства дескрипторами защиты за счет применения централизованного файла метаданных $Secure, в котором хранится только один экземпляр каждого дескриптора защиты на данном томе.
Файл $Secure содержит два атрибута индексов ($SDH и $SIJ), а также атрибут потока данных $SDS, как показано на рис. 12–45. NTFS назначает каждому уникальному дескриптору защиты на томе внутренний для NTFS идентификатор защиты (не путать с SID, который уникально идентифицирует учетные записи компьютеров и пользователей) и хэширует дескриптор защиты по простому алгоритму. Хэш является потенциально неуникальным «стенографическим» представлением дескриптора. Элементы в индексе $SDH увязывают эти хэши с местонахождением дескриптора защиты внутри атрибута данных $SDS, а элементы индекса $SII сопоставляют NTFS-идентификаторы защиты с местонахождением дескриптора защиты в атрибуте данных $SDS.
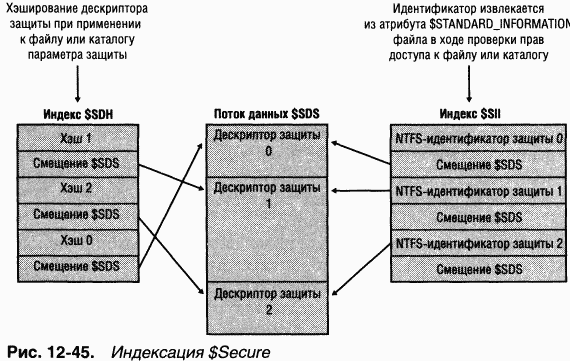 |
Когда вы применяете дескриптор защиты к файлу или каталогу, NTFS получает хэш этого дескриптора и просматривает индекс $SDH, пытаясь найти совпадение. NTFS сортирует элементы индекса $SDH по хэшам дескрипторов защиты и хранит эти элементы в структуре вида b+ tree. Обнаружив совпадение для дескриптора в индексе $SDH, NTFS находит смещение дескриптора защиты от смещения элемента и считывает дескриптор из атрибута $SDS. Если хэши совпадают, а дескрипторы — нет, NTFS ищет следующее совпадение в индексе $SDH. Когда NTFS находит точное совпадение, файл или каталог, к которому вы применяете дескриптор защиты, может ссылаться на существующий дескриптор в атрибуте $SDS. Тогда NTFS считывает NTFS-идентифика-тор защиты из элемента $SDH и сохраняет его в атрибуте $STANDARD_ INFORMATION файла или каталога. Атрибут $STANDARD_INFORMATION, имеющийся у всех файлов и каталогов, хранит базовую информацию о файле, в том числе его атрибуты, временные метки и идентификатор защиты.
Если NTFS не обнаруживает в индексе $SDH элемент с дескриптором защиты, совпадающим с тем, который вы применяете, значит, ваш дескриптор уникален в пределах данного тома, и NTFS присваивает ему новый внутренний идентификатор защиты. Такие идентификаторы являются 32-битными значениями, но SID обычно в несколько раз больше, поэтому представление SID в виде NTFS-идентификаторов защиты экономит место в атрибуте $STANDARD_INFORMATION. NTFS включает дескриптор защиты в атрибут $SDS, который сортируется в структуру вида b+ tree по NTFS-идентификатору защиты, а потом добавляет его в элементы индексов $SDH и $SII, ссылающиеся на смещение дескриптора в данных $SDS.
Когда приложение пытается открыть файл или каталог, NTFS использует индекс $SII для поиска дескриптора защиты этого файла или каталога. NTFS считывает внутренний идентификатор защиты файла или каталога из атрибута SSTANDARD_INFORMATION записи MFT Затем по индексу $SII файла $Secure она находит элемент с нужным идентификатором в атрибуте $SDS. По смещению в атрибуте $SDS NTFS считывает дескриптор защиты и завершает проверку прав доступа. NTFS хранит последние 32 дескриптора защиты, к которым было обращение, вместе с их элементами $SII в кэше, чтобы впоследствии была возможность обращаться только к файлу $Secure.
NTFS не удаляет элементы в файле $Secure, даже если на них не ссылаются никакие файлы или каталоги на томе. Это приводит лишь к незначительному увеличению места, занимаемого файлом $Secure, так как на большинстве томов, даже если они используются уже весьма долго, уникальных дескрипторов защиты сравнительно немного.
Механизм универсальной индексации позволяет NTFS повторно использовать дескрипторы защиты для файлов и каталогов с одинаковыми параметрами защиты. По индексу $SII NTFS быстро находит дескриптор защиты в файле SSecure при проверках прав доступа, а по индексу $SDH определяет, хранится ли применяемый к файлу или каталогу дескриптор защиты в файле SSecure, и, если да, использует этот дескриптор повторно.
Как уже упоминалось,
Поддержка восстановления в NTFS гарантирует, что в случае отказа электропитания или аварии системы ни одна операция файловой системы (транзакция) не останется незавершенной; при этом структура дискового тома будет сохранена. NTFS включает утилиту Chkdsk, которая позволяет устранять последствия катастрофических повреждений диска, вызванных аппаратными ошибками ввода-вывода (например, из-за аварийных секторов на диске, электрических аномалий или сбоев в работе диска) либо ошибками в программном обеспечении. Наличие средств восстановления NTFS уменьшает потребность в использовании Chkdsk.
Как уже упоминалось в разделе «Восстанавливаемость», NTFS использует схему на основе обработки транзакций. Эта стратегия гарантирует полное восстановление диска, которое производится исключительно быстро (за считанные секунды) даже в случае самых больших дисков. NTFS ограничивается восстановлением данных файловой системы, гарантируя, что пользователь по крайней мере никогда не потеряет весь том из-за повреждения файловой системы. Ho, если приложение не выполнило определенных действий, например не сбросило на диск кэшированные файлы, NTFS не гарантирует полное восстановление пользовательских данных в случае краха. Защита пользовательских данных на основе технологии обработки транзакций предусматривается в большинстве СУБД для Windows, например в Microsoft SQL Server. Microsoft не стала реализовать восстановление пользовательских данных на уровне файловой системы, так как приложения обычно поддерживают свои схемы восстановления, оптимизированные под тот тип данных, с которыми они работают.
B следующих разделах рассказывается об эволюции средств обеспечения надежности файловой системы, и в этом контексте вводится концепция восстанавливаемых файловых систем с подробным обсуждением схемы протоколирования транзакций, за счет которой NTFS регистрирует изменения в структурах данных файловой системы. Кроме того, мы поясним, как NTFS восстанавливает том в случае сбоя системы.
Создание восстанавливаемой файловой системы можно рассматривать как еще один шаг в эволюции архитектуры файловых систем. B прошлом были распространены два основных подхода к организации поддержки ввода-вывода и кэширования в файловых системах:
Далее мы кратко рассмотрим два типа файловых систем, наиболее распространенные в настоящее время, и присущие им внутренние противоречия между безопасностью и производительностью. B третьем подразделе будет описан подход к восстановлению, принятый в NTFS, и его отличие от двух вышеупомянутых стратегий.
B случае аварии операционной системы или сбоя электропитания операции ввода-вывода, выполняемые в данный момент, немедленно прерываются. B зависимости от того, какие операции ввода-вывода выполнялись и насколько далеко продвинулось их выполнение, такое прерывание может нарушить целостность файловой системы. B данном контексте нарушение целостности — это повреждение файловой системы: например, имя файла появляется в списке каталога, но файловая система не знает, где он находится, или не может обратиться к его содержимому. B самых тяжелых случаях повреждение файловой системы может привести к потере всего тома.
Файловая система с точной записью не пытается предотвратить нарушения целостности. Вместо этого она упорядочивает операции записи так, что авария системы в худшем случае вызовет предсказуемые, некритичные рассогласования, которые файловая система сможет в любой момент устранить.
Когда файловая система (какого бы типа она ни была) получает запрос на обновление содержимого диска, она должна выполнить несколько подопераций, прежде чем обновление будет завершено. B файловой системе, использующей стратегию точной записи, эти подоперации всегда записывают свои данные на диск последовательно. При выделении дискового пространства, например для файла, файловая система сначала устанавливает некоторые биты в своей битовой карте, после чего выделяет место для файла. Если сбой питания происходит сразу после того, как были установлены эти биты, файловая система точной записи теряет доступ к той части диска, которая была представлена установленными битами, но существующие данные не разрушаются.
Упорядочение операций записи также означает, что запросы на ввод-вывод выполняются в порядке их поступления. Если один процесс выделяет дисковое пространство и вскоре после этого другой процесс создает файл, файловая система с точной записью завершает выделение дискового пространства до того, как начнет создавать файл, — иначе перекрытие подопераций из двух запросов ввода-вывода могло бы привести к нарушению целостности.
Основное преимущество файловых систем с точной записью в том, что в случае сбоя дисковый том остается целостным и его можно использовать дальше — немедленный запуск утилиты исправления тома не обязателен. Такая утилита нужна для исправления предсказуемых, неразрушительных нарушений целостности диска, которые возникли в результате сбоя, но ее можно запустить в удобное время, обычно при перезагрузке системы.
Файловая система с точной записью жертвует производительностью ради надежности. Она повышает производительность за счет стратегии кэширования с
Метод кэширования по алгоритму отложенной записи дает несколько преимуществ, увеличивающих производительность. Во-первых, уменьшается общее число операций записи на диск. Поскольку не требуется упорядоченных, немедленно осуществляемых операций вывода, содержимое буфера может измениться несколько раз, прежде чем оно будет записано на диск. Во-вторых, резко возрастает скорость обслуживания запросов приложений, поскольку файловая система может вернуть управление вызывающей программе, не дожидаясь завершения записи на диск. Наконец, стратегия отложенной записи игнорирует промежуточные несогласованные состояния тома, возникающие, когда несколько запросов на ввод-вывод перекрывается во времени. Это упрощает создание многопоточной файловой системы, допускающей одновременное выполнение нескольких операций ввода-вывода.
Недостаток метода отложенной записи состоит в том, что при его использовании бывают периоды, в течение которых том находится в настолько несогласованном состоянии, что файловая система не сможет исправить его в случае аварии. Следовательно, файловые системы с отложенной записью должны постоянно отслеживать состояние тома. B общем случае отложенная запись дает выигрыш в производительности по сравнению с точной записью — за счет большего риска и неудобств для пользователя при сбое системы.
Восстанавливаемая файловая система типа NTFS превосходит по надежности файловые системы с точной записью и при этом достигает уровня производительности файловых систем с отложенной записью. Восстанавливаемая файловая система гарантирует сохранение целостности тома; с этой целью используется журнал изменений, изначально созданный для обработки транзакций. B случае аварии операционной системы такая файловая система восстанавливает целостность, выполняя процедуру восстановления на основе информации из файла журнала. Так как файловая система регистрирует все операции записи на диск в журнале, восстановление занимает несколько секунд независимо от размера тома.
Процедура восстановления в восстанавливаемой файловой системе является точной и гарантирует возвращение тома в согласованное состояние. Неадекватные результаты восстановления, характерные для файловых систем с отложенной записью, в NTFS исключены.
За высокую надежность восстанавливаемой файловой системы приходится расплачиваться. При каждой транзакции, изменяющей структуру тома, в файл журнала требуется заносить по одной записи на каждую подоперацию транзакции. Файловая система уменьшает издержки протоколирования за счет объединения записей файла журнала в пакеты: за одну операцию ввода-вывода в журнал добавляется сразу несколько записей. Кроме того, восстанавливаемая файловая система может применять алгоритмы оптимизации, используемые файловыми системами с отложенной записью. Она может даже увеличить интервалы между сбросами кэша на диск, так как файловую систему можно восстановить, если авария произошла до того, как изменения переписаны из кэша на диск. Такой рост в производительности кэша компенсирует и часто даже перевешивает издержки, вызванные протоколированием транзакций.
Ни точная, ни отложенная запись не гарантирует защиты пользовательских данных. Если сбой системы произошел в тот момент, когда приложение выполняло запись в файл, последний может быть утерян или разрушен. Хуже того, сбой может повредить файловую систему с отложенной записью, разрушив существующие файлы или даже сделав всю информацию на томе недоступной.
Восстанавливаемая файловая система NTFS использует стратегию, повышающую ее надежность по сравнению с традиционными файловыми системами. Во-первых, восстанавливаемость NTFS гарантирует, что структура тома не будет разрушена, так что в случае сбоя системы все файлы останутся доступными.
Во-вторых, хотя NTFS не гарантирует сохранности пользовательских данных в случае сбоя системы (некоторые изменения в кэше могут быть потеряны), приложения могут использовать преимущества сквозной записи и сброса кэша NTFS для гарантии того, что изменения файлов будут записываться на диск в должное время. Как сквозная запись (принудительная немедленная запись на диск), так и сброс кэша (принудительная запись на диск содержимого кэша) — операции вполне эффективные. NTFS не требуется дополнительного ввода-вывода для сброса на диск изменений нескольких различных структур данных файловой системы, так как изменения в этих структурах регистрируются в файле журнала (в ходе единственной операции записи); если произошел сбой и содержимое кэша потеряно, изменения файловой системы могут быть восстановлены по информации из журнала. Более того, NTFS в отличие от FAT гарантирует, что сразу после операции сквозной записи или сброса кэша пользовательские данные останутся целостными и будут доступны, даже если вслед за этим произойдет сбой системы.
Восстанавливаемость NTFS обеспечивается методикой обработки транзакций, называемой
Сервис файла журнала (log file service, LFS) — это набор процедур режима ядра, локализованных в драйвере NTFS, который она использует для доступа к файлу журнала. Хотя LFS изначально был разработан для того, чтобы предоставлять средства протоколирования и восстановления более чем одному клиенту, он используется только NTFS. Вызывающая программа, в данном случае NTFS, передает LFS указатель на открытый объект «файл», который определяет файл, выступающий в роли журнала. LFS либо инициализирует новый журнал, либо вызывает диспетчер кэша для доступа к существующему журналу через кэш, как показано на рис. 12–46.
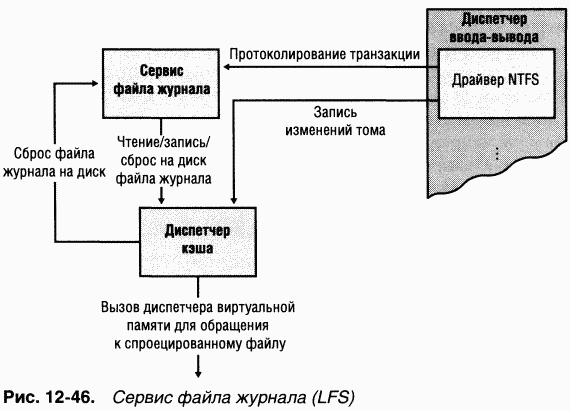 |
LFS делит файл журнала на две части:
 |
NTFS вызывает LFS для чтения и записи области перезапуска. B этой области NTFS хранит информацию о контексте, например позицию в области протоколирования, откуда начнется чтение при восстановлении после сбоя системы. Ha тот случай, если область перезапуска будет разрушена или по каким-либо причинам станет недоступной, LFS создает ее копию. Остальная часть журнала транзакций — это область протоколирования, в которой находятся записи транзакций, обеспечивающие восстановление тома после сбоя. LFS создает иллюзию бесконечности журнала транзакций за счет его циклического повторного использования (в то же время не перезаписывая нужную информацию). Для идентификации записей, помещенных в журнал, LFS использует
NTFS никогда не выполняет чтение/запись транзакций в журнал напрямую. LFS предоставляет сервисы, которые NTFS вызывает для открытия файла журнала, помещения в него записей, чтения записей из журнала в прямом и обратном порядке, сброса записей журнала до заданного LSN или установки логического начала журнала на больший LSN. B процессе восстановления NTFS вызывает LFS для чтения записей журнала в прямом направлении, чтобы повторить все транзакции, которые запротоколированы в журнале, но не записаны на диск в момент сбоя. NTFS также обращается к LFS для чтения записей в обратном направлении, чтобы отменить (или откатить) все транзакции, не полностью запротоколированные перед аварией системы, и установить начало файла журнала на запись с большим LSN после того, как старые записи журнала стали не нужны.
Вот как система обеспечивает восстановление тома.
1. Сначала NTFS вызывает LFS для записи в кэшируемый файл журнала любых транзакций, модифицирующих структуру тома.
2. NTFS модифицирует том (также в кэше).
3. Диспетчер кэша сообщает LFS сбросить файл журнала на диск. (Этот сброс реализуется LFS путем обратного вызова диспетчера кэша с указанием страниц памяти, подлежащих выводу на диск; см. рис. 12–46.)
4. Сбросив на диск журнал транзакций, диспетчер кэша записывает на диск изменения тома (результаты операций над метаданными). Эта последовательность действий гарантирует: если завершить изменение файловой системы не удастся, соответствующие транзакции можно будет считать из журнала и либо повторить, либо отменить в процессе восстановления файловой системы.
Восстановление файловой системы начинается автоматически при первом обращении к дисковому тому после перезагрузки. NTFS проверяет, применялись ли к тому транзакции, запротоколированные в журнале до сбоя, и, если нет, повторяет их. NTFS гарантирует и отмену транзакций, не полностью запротоколированных до сбоя, так что вызываемые ими изменения не появятся на томе.
LFS позволяет своим клиентам помещать в журналы транзакций записи любого типа. NTFS использует несколько типов записей, два из которых —
K ним относится большинство записей, которые NTFS помещает в журнал транзакций. Каждая такая запись содержит два вида информации.
• Информация для повтора (redo information) Описывает, как вновь применить к дисковому тому одну подоперацию полностью запротоколированной транзакции, если сбой системы произошел до того, как транзакция была переписана из кэша на диск.
• Информация для отмены (undo information) Описывает, как обратить изменения, вызванные одной подоперацией транзакции, которая в момент сбоя была запротоколирована лишь частично. Ha рис. 12–48 показаны три записи модификации в файле журнала. Каждая запись представляет одну подоперацию транзакции, создающей новый файл. Информация для повтора в каждой записи модификации сообщает NTFS, как повторно применить данную подоперацию к дисковому тому, а информация для отмены — как откатить (отменить) эту подоперацию.
 |
После протоколирования транзакции (в данном примере — вызовом LFS до помещения трех записей модификации в файл журнала) NTFS выполняет в кэше подоперации этой транзакции, изменяющие том. Закончив обновление кэша, NTFS помещает в журнал еще одну запись, которая помечает всю транзакцию как завершенную. Эта подоперация известна как
При восстановлении после сбоя системы NTFS просматривает журнал и повторяет все зафиксированные транзакции. Даже если NTFS и завершила транзакцию до момента сбоя системы, ей неизвестно, были ли изменения тома своевременно переписаны на диск диспетчером кэша. Модификации, выполненные в кэше, могли быть потеряны при сбое. Следовательно, NTFS выполняет зафиксированную транзакцию снова, чтобы гарантировать актуальность состояния диска.
После повтора всех зафиксированных транзакций NTFS отыскивает в журнале такие, которые не были зафиксированы к моменту сбоя, и откатывает каждую запротоколированную подоперацию. B случае, представленном на рис. 12–48, NTFS вначале должна была бы отменить подоперацию T1c, после чего перейти по указателям назад и отменить T1b. Переход по указателям в обратном направлении и отмена подопераций продолжались бы до тех пор, пока NTFS не достигла бы первой подоперации транзакции. Следуя указателям, NTFS определяет, сколько и какие записи модификации нужно отменить для того, чтобы откатить транзакцию.
Информация для повтора и отмены может быть выражена либо физически, либо логически. Физическое описание задает модификации тома как диапазоны байтов на диске, которые следует изменить, переместить и т. д., а логическое — представляет модификации в терминах операций, например «удалить файл A.dat». Как самый низкий уровень программного обеспечения, поддерживающего структуру файловой системы, NTFS использует записи модификации с физическими описаниями. Однако для программного обеспечения обработки транзакций и других приложений записи модификации в логическом виде могут быть удобнее, поскольку логическое представление обновлений тома компактнее физических. Логическое описание требует участия NTFS в выполнении действий, связанных с такими операциями, как удаление файла.
NTFS генерирует записи модификации (обычно несколько) для каждой из следующих транзакций:
• создание файла;
• удаление файла;
• расширение файла;
• урезаниефайла;
• установка файловой информации;
• переименование файла;
• изменение прав доступа к файлу
Информация для повтора и отмены в записи модификации должна быть очень точной, иначе при отмене транзакции, восстановлении после сбоя системы или даже в ходе нормальной работы NTFS может попытаться повторить транзакцию, которая уже выполнена, или, наоборот, отменить транзакцию, которая никогда не выполнялась либо уже отменена. Аналогичным образом NTFS может попытаться повторить или отменить транзакцию, включающую нескольких записей модификации, которые не все были применены к диску. Формат записей модификации должен гарантировать, что лишние операции повтора или отмены будут
Помимо записей модификации NTFS периодически помещает в файл журнала запись контрольной точки, как показано на рис. 12–49.
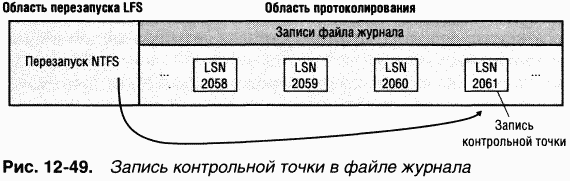 |
Запись контрольной точки помогает NTFS определить, какая обработка нужна для восстановления тома, если сбой произошел сразу после добавления этой записи в журнал. Благодаря записи контрольной точки NTFS, например, знает, как далеко назад ей нужно пройти по журналу, чтобы начать восстановление. Добавив новую запись контрольной точки, NTFS записывает ее LSN в область перезапуска, так что, начиная восстановление после сбоя системы, она быстро находит самую последнюю запись контрольной точки.
Хотя LFS представляет NTFS, будто журнал транзакций безразмерен, на самом деле он не бесконечен. Значительный размер журнала транзакций и частая вставка записей контрольной точки (операция, обычно освобождающая место в файле журнала) делают вероятность его переполнения достаточно малой. Тем не менее LFS учитывает такую возможность, отслеживая несколько значений:
• размер свободного пространства в журнале;
• размер пространства, необходимого для добавления в журнал следующей записи и для отмены этого действия (если это вдруг потребуется);
• размер пространства, нужного для отката всех активных (не зафиксированных) транзакций (если это вдруг потребуется).
Если в журнале не хватает места для суммы последних двух значений из списка, LFS сообщает об ошибке переполнения файла журнала, и NTFS генерирует исключение. Обработчик исключений NTFS откатывает текущую транзакцию и помещает ее в очередь для последующего перезапуска.
Чтобы освободить пространство в журнале транзакций, NTFS должна временно приостановить ввод-вывод в системе. Для этого она блокирует создание и удаление файлов, после чего запрашивает монопольный доступ ко всем системным файлам и разделяемый доступ ко всем пользовательским файлам. Постепенно активные транзакции либо завершаются успешно, либо вызывают исключение переполнения файла журнала. B последнем случае NTFS откатывает их, а затем помещает в очередь.
Заблокировав вышеописанным способом выполнение транзакций при операциях над файлами, NTFS вызывает диспетчер кэша для сброса на диск еще не записанных туда данных, в том числе данных файла журнала. После того как все успешно записано на диск, данные в журнале NTFS становятся ненужными. NTFS устанавливает начало журнала на текущую позицию, что делает журнал «пустым». Затем NTFS перезапускает транзакции, поставленные ранее в очередь. Так что за исключением короткой паузы в обработке ввода-вывода ошибка переполнения файла журнала не оказывает влияния на выполняемые программы.
Описанный сценарий — один из примеров того, как NTFS использует файл журнала не только для восстановления файловой системы, но и для исправления ошибок при нормальной работе.
NTFS автоматически выполняет восстановление диска при первом обращении к нему какой-либо программы после загрузки системы. (Если восстановление не требуется, весь процесс тривиален.) При восстановлении используются две таблицы, которые NTFS поддерживает в памяти.
•
•
Каждые 5 секунд NTFS добавляет в файл журнала транзакций запись контрольной точки. Непосредственно перед этим она обращается к LFS для сохранения в журнале текущей копии таблицы транзакций и таблицы измененных страниц. Затем NTFS запоминает в записи контрольной точки LSN записей журнала, содержащих копии таблиц. B начале процесса восстановления после сбоя NTFS обращается к LFS для поиска записей журнала транзакций, содержащих самую последнюю запись контрольной точки и самые последние копии упомянутых выше таблиц. Затем NTFS копирует эти таблицы в память.
Обычно за последней записью контрольной точки в журнале транзакций находится еще несколько записей модификации. Эти записи соответствуют обновлениям тома, произошедшим после того, как запись контрольной точки была помещена в журнал. NTFS должна обновить таблицу транзакций и таблицу измененных страниц, включив в них информацию из этих дополнительных записей. После обновления таблиц NTFS использует их, а также содержимое журнала транзакций для обновления собственно тома.
При восстановлении тома NTFS выполняет три прохода по журналу транзакций, загружая его в память на первом проходе, чтобы минимизировать объем дискового ввода-вывода. Каждый проход имеет свое назначение:
• анализ;
• повтор транзакций; • отмена транзакций.
При
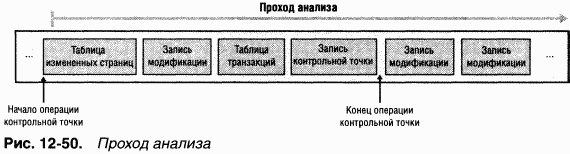 |
Большинство записей модификации, расположенных в журнале после начала операции контрольной точки, представляет собой изменение либо таблицы транзакций, либо таблицы измененных страниц. Например, если запись модификации относится к фиксации транзакции, то транзакция, которую представляет данная запись, должна быть удалена из таблицы транзакций. Аналогично, если запись модификации относится к обновлению страницы, изменяющему структуру данных файловой системы, нужно внести соответствующую поправку в таблицу измененных страниц.
После того как таблицы в памяти приведены в актуальное состояние, NTFS просматривает их, чтобы определить LSN самой старой записи модификации, которая регистрирует операцию, не выполненную над диском. Таблица транзакций содержит LSN незафиксированных (незавершенных) транзакций, а таблица измененных страниц — LSN записей, соответствующих модификациям кэша, не отраженным на диске. LSN самой старой записи, найденной NTFS в этих двух таблицах, определяет, откуда начнется проход повтора. Однако, если последняя запись контрольной точки окажется более ранней, NTFS начнет проход повтора именно с нее.
Ha
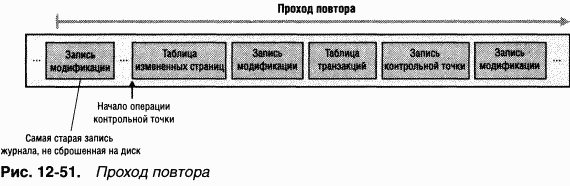 |
Когда NTFS достигает конца журнала транзакций, она уже обновила кэш необходимыми модификациями тома, и подсистема отложенной записи, принадлежащая диспетчеру кэша, может начать переписывать содержимое кэша на диск в фоновом режиме.
Завершив проход повтора, NTFS начинает
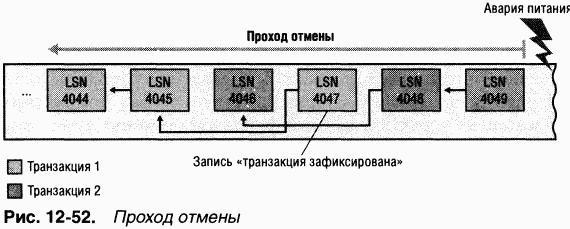 |
Допустим, в ходе транзакции 2 создавался файл. Эта операция состоит из трех подопераций (каждая со своей записью модификации). Записи модификации, относящиеся к одной транзакции, связываются в журнале обратными указателями, поскольку эти записи обычно не располагаются одна за другой.
B таблице транзакций NTFS для каждой незавершенной транзакции хранится LSN записи модификации, помещенной в журнал последней. B данном примере таблица транзакций сообщает, что для транзакции 2 это запись с LSN 4049. NTFS выполняет откат транзакции 2, как показано на рис. 12–53 (справа налево).
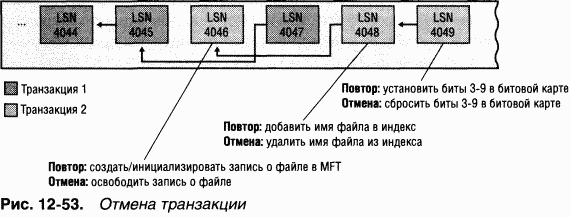 |
Найдя LSN 4049, NTFS извлекает информацию для отмены и выполняет отмену, сбрасывая биты 3–9 в своей битовой карте. Затем NTFS следует по обратному указателю к LSN 4048, который указывает ей удалить новое имя файла из индекса имен файлов. Наконец, NTFS переходит по последнему обратному указателю и освобождает запись MFT, зарезервированную для данного файла, в соответствии с информацией из записи модификации с LSN 4046. Ha этом откат транзакции 2 закончен. Если имеются другие незавершенные транзакции, NTFS повторяет ту же процедуру для их отката. Поскольку отмена транзакций изменяет структуру файловой системы на томе, NTFS должна протоколировать операцию отмены в журнале транзакций. B конце концов, при восстановлении может снова произойти сбой питания, и NTFS придется выполнить повтор операций отмены!
Когда проход отмены завершен, том возвращается в согласованное состояние. B этот момент NTFS сбрасывает на диск изменения кэша, чтобы гарантировать правильность содержимого тома. Далее NTFS записывает «пустую» область перезапуска, указывающую, что том находится в согласованном состоянии и что, если система сразу потерпит еще одну аварию, никакого восстановления не потребуется. Ha этом восстановление заканчивается.
NTFS гарантирует, что восстановление вернет том в некое существовавшее ранее целостное состояние, но не обязательно в непосредственно предшествовавшее сбою. NTFS не может дать такой гарантии, поскольку для большей производительности она использует алгоритм отложенной фиксации (lazy commit), а значит, сброс журнала транзакций из кэша на диск не выполняется немедленно всякий раз, когда добавляется запись «транзакция зафиксирована». Вместо этого несколько записей фиксации транзакций объединяются в пакет и записываются совместно — либо когда диспетчер кэша вызывает LFS для сброса журнала на диск, либо когда LFS помещает в журнал новую запись контрольной точки (каждые 5 секунд). Другая причина, по которой том не всегда возвращается к самому последнему состоянию, — в момент сбоя системы могли быть активны несколько параллельных транзакций, и одни записи фиксации этих транзакций были перенесены на диск, а другие — нет. Согласованное состояние тома, полученное в результате восстановления, отражает только те транзакции, чьи записи фиксации успели попасть на диск.
NTFS применяет журнал транзакций не только для восстановления тома, но и для других целей, реализация которых становится возможной за счет протоколирования транзакций. Файловые системы обязательно включают большой объем кода для обработки ошибок, возникающих в процессе обычного файлового ввода-вывода. Поскольку NTFS протоколирует каждую транзакцию, модифицирующую структуру тома, она может использовать журнал транзакций для восстановления после ошибок файловой системы и таким образом существенно упростить код обработки ошибок. Ошибка переполнения журнала транзакций, описанная ранее, — один из примеров использования протоколирования транзакций для обработки ошибок.
Большинство ошибок ввода-вывода, получаемых программой, не является ошибками файловой системы, и поэтому NTFS не может исправить их самостоятельно. Например, получив запрос на создание файла, NTFS может начать с создания записи в MFT, после чего ввести имя файла в индекс каталога. Однако при попытке выделить по своей битовой карте пространство для нового файла она может обнаружить, что диск заполнен, и запрос на создание файла удовлетворить не удастся. Тогда NTFS использует информацию из журнала транзакций для отмены уже выполненной части операции и освобождения структур данных, зарезервированных ею для файла. Затем ошибка «диск заполнен» возвращается вызывающей программе, которая и должна предпринять соответствующие действия.
Диспетчеры томов Windows — FtDisk (для базовых дисков) и LDM (для динамических) — могут восстанавливать данные из плохого (аварийного) сектора на отказоустойчивом томе, но, если жесткий диск не является SCSI-диском или если на нем больше нет резервных секторов, они не в состоянии заменить плохой сектор новым (подробнее о диспетчерах томов см. главу 10). B таком случае, когда файловая система считывает данные из плохого сектора, диспетчер томов восстанавливает информацию и возвращает ее вместе с соответствующим предупреждением.
Файловая система FAT никак не обрабатывает это предупреждение. Более того, ни эта файловая система, ни диспетчеры томов не ведут учет плохих секторов, поэтому, чтобы диспетчер томов не повторял все время восстановление данных из плохого сектора, пользователь должен запустить утилиту Chkdsk или Format. Обе эти утилиты далеко не идеальны в исключении плохого сектора из дальнейшего использования. Chkdsk требует много времени для поиска и удаления плохих секторов, a Format уничтожает все данные в форматируемом разделе.
NTFS-эквивалент механизма замены секторов динамически заменяет кластер, содержащий плохой сектор, и ведет учет плохих кластеров, чтобы предотвратить их дальнейшее использование. (Вспомните, что NTFS адресуется к логическим кластерам, а не к физическим секторам.) Эта функциональность NTFS активизируется, если диспетчер томов не может заменить плохой сектор. Когда FtDisk возвращает предупреждение о плохом секторе или когда драйвер диска сообщает об ошибке, связанной с плохим сектором, NTFS выделяет новый кластер для замены того, который содержит плохой сектор. NTFS копирует данные, восстановленные диспетчером томов, в новый кластер, чтобы снова добиться избыточности данных.
Ha рис. 12–54 показана запись MFT для пользовательского файла, в одном из групп которого имеется плохой сектор. Когда NTFS получает ошибку, связанную с плохим сектором, она присоединяет содержащий его кластер к своему файлу плохих кластеров. Это предотвращает повторное выделение данного кластера другому файлу. Затем NTFS выделяет новый кластер и изменяет сопоставление VCN-LCN для файла так, чтобы оно указывало на этот кластер. Данная процедура, известная как
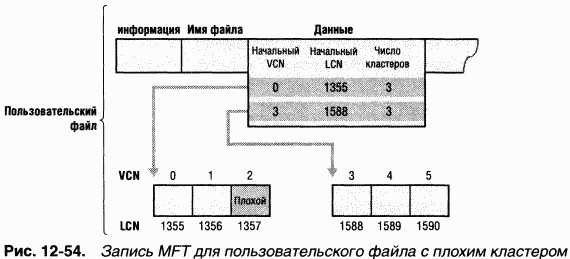 |
Появление плохих секторов нежелательно, но когда они все же появляются, лучшее решение предлагается NTFS в сочетании с диспетчером томов. Если плохой сектор находится на томе с избыточностью данных, диспетчер томов восстанавливает данные и замещает сектор, если это возможно. Если сектор заменить нельзя, диспетчер томов возвращает предупреждение NTFS, которая заменяет кластер с плохим сектором.
Если том не сконфигурирован как отказоустойчивый, данные из плохого сектора восстановить нельзя. Когда том отформатирован для FAT и диспетчер томов не может восстановить данные, чтение из плохого сектора дает непредсказуемые результаты. Если в плохом секторе располагались какие-либо управляющие структуры файловой системы, может быть потерян целый файл или группа файлов (а иногда и весь диск). B лучшем случае будет потеряна часть данных файла (как правило, все файловые данные, расположенные в данном секторе и за ним). Более того, FAT скорее всего повторно выделит плохой сектор под другой файл, в результате чего проблема возникнет снова.
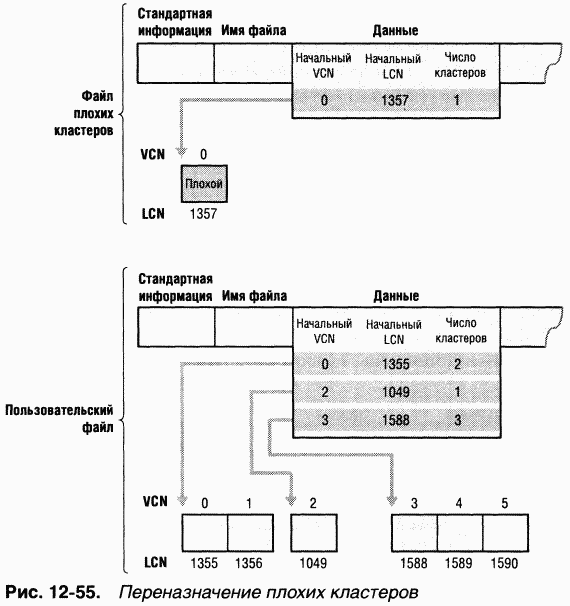 |
Как и другие файловые системы, NTFS не может восстановить данные из плохого сектора без помощи диспетчера томов. Однако она значительно сокращает ущерб, который наносится появлением плохого сектора. Если NTFS обнаруживает плохой сектор в ходе операции чтения, она переназначает кластер, как показано на рис. 12–55. Если том не сконфигурирован для избыточного хранения информации, NTFS возвращает ошибку чтения вызывающей программе. Хотя данные, находившиеся в этом кластере, теряются, остаток файла и сама файловая система сохраняются, вызывающая программа может соответствующим образом отреагировать на потерю данных, а плохой кластер больше не будет использоваться при распределении пространства на томе. Если NTFS обнаруживает плохой кластер во время записи, а не чтения, она переназначает его до выполнения операции записи и тем самым вообще избегает потери данных.
Ta же процедура восстановления используется, когда в аварийном секторе хранятся данные файловой системы. Если он находится на томе с избыточностью данных, NTFS динамически заменяет соответствующий кластер, используя данные, восстановленные диспетчером томов. Если том не избыточный, восстановить данные нельзя, и NTFS устанавливает в файле тома бит, указывающий, что том поврежден. При перезагрузке системы NTFS-утилита Chkdsk проверяет этот бит и, если он установлен, исправляет повреждение файловой системы, реконструируя метаданные NTFS.
Крайне редко повреждение файловой системы может произойти даже на отказоустойчивом томе: двойная ошибка способна разрушить и данные файловой системы, и информацию для их восстановления. Если авария системы происходит в тот момент, когда NTFS сохраняет, например, зеркальную копию записи MFT, индекса имен файлов или журнала транзакций, то зеркальная копия этих данных файловой системы обновляется не полностью. Если после перезагрузки системы ошибка, связанная с плохим сектором, возникает в том же месте основного диска, где находится частично записанная зеркальная копия, NTFS не может восстановить информацию с зеркального диска. Для детекции таких повреждений системных данных в NTFS реализована специальная схема. Если обнаружено нарушение целостности, в файле тома устанавливается бит повреждения, в результате чего при следующей загрузке системы метаданные NTFS будут реконструированы Chkdsk. Так как в отказоустойчивой дисковой конфигурации повреждение данных файловой системы маловероятно, потребность в Chkdsk возникает редко. Эта утилита позиционируется как дополнительная мера предосторожности, а не как основное средство восстановления информации.
Использование Chkdsk в NTFS существенно отличается от ее использования в FAT Перед записью на диск FAT устанавливает бит изменения тома, который сбрасывается по завершении модификации тома. Если сбой системы происходит при выполнении операции вывода, бит остается установленным, и после перезагрузки машины запускается Chkdsk. B NTFS утилита Chkdsk запускается, только когда обнаруживаются неожиданные или нечитаемые данные файловой системы и NTFS не может восстановить их с избыточного тома или из избыточных структур данных файловой системы на обычном томе. (Система дублирует загрузочный сектор, равно как и части MFT, необходимые для загрузки системы и выполнения процедуры восстановления NTFS. Эта избыточность гарантирует, что NTFS всегда сможет загрузиться и восстановить сама себя.)
B таблицу 12-6 сведены данные о том, что происходит при появлении плохого сектора на дисковом томе (отформатированном для одной из файловых систем Windows) в различных ситуациях, описанных в данном разделе.
 |
1. Диспетчер томов не может заменять секторы ни в одном из следующих случаев: 1) жесткие диски, отличные от SCSI, не поддерживают стандартный интерфейс для замены секторов; 2) некоторые жесткие диски не имеют аппаратной поддержки замены секторов, а SCSI-диски, у которых она есть, могут со временем исчерпать весь резерв секторов.
2. Отказоустойчивым является том одного из следующих типов: зеркальный или RAID-5. При записи данные не теряются: NTFS переназначает кластер до выполнения записи.
Если том, на котором появился плохой сектор, сконфигурирован как отказоустойчивый, а жесткий диск поддерживает замену секторов и его запас резервных секторов еще не исчерпан, то тип файловой системы (FAT или NTFS) не имеет значения. Диспетчер томов заменяет плохой сектор, не требуя вмешательства со стороны пользователя или файловой системы.
Если плохой сектор появился на жестком диске, не поддерживающем замену секторов, то за переназначение плохого сектора или, как в случае NTFS, кластера, в котором находится плохой сектор, отвечает файловая система. FAT не умеет переназначать секторы или кластеры.
EFS (Encrypting File System) использует средства поддержки шифрования. При первом шифровании файла EFS назначает учетной записи пользователя, шифрующего этот файл, криптографическую пару — закрытый и открытый ключи. Пользователи могут шифровать файлы с помощью Windows Explorer; для этого нужно открыть диалоговое окно Properties (Свойства) применительно к нужному файлу, щелкнуть кнопку Advanced (Другие) и установить флажок Encrypt Contents To Secure Data (Шифровать содержимое для защиты данных), как показано на рис. 12–56. Пользователи также могут шифровать файлы с помощью утилиты командной строки
По умолчанию FEK шифруется в Windows 2000 и Windows XP по алгоритму DESX, а в Windows XP с Service Pack 1 (или выше) и Windows Server 2003 — по алгоритму AES. B версиях Windows, разрешенных к экспорту за пределы США, драйвер EFS реализует 56-битный ключ шифрования DESX, тогда как в версии, подлежащей использованию только в США, и в версиях с пакетом для 128-битного шифрования длина ключа DESX равна 128 битам. Алгоритм AES в Windows использует 256-битные ключи. Применение 3DES разрешает доступ к более длинным ключам, поэтому, если вам требуется более высокая стойкость FEK, вы можете включить шифрование 3DES одним из двух способов: как алгоритм шифрования для всех криптографических сервисов в системе или только для EFS.
Чтобы 3DES стал алгоритмом шифрования для всех системных криптографических сервисов, запустите редактор локальной политики безопасности, введя secpol.msc в диалоговом окне Run (Запуск программы), и откройте узел Security Options (Параметры безопасности) под Local Policies (Локальные политики). Найдите параметр System Cryptography: Use FIPS Compliant Algorithms For Encryption, Hashing And Signing (Системная криптография: использовать FIPS-совмести-мые алгоритмы для шифрования, хеширования и подписывания) и включите его.
Чтобы активизировать 3DES только для EFS, создайте DWORD-параметр HKLM\SOFWARE\Microsoft\Windows NT\CurrentVersion\EFS\ AlgorithmID, присвойте ему значение 0x6603 и перезагрузите систему.
 |
Рис. 12–56. Шифрование файлов через пользовательский интерфейс Windows Explorer
Для шифрования FEK используется алгоритм криптографической пары, а для шифрования файловых данных — DESX, AES или 3DES (все это алгоритмы симметричного шифрования, в которых применяется один и тот же ключ для шифрования и дешифрования). Как правило, алгоритмы симметричного шифрования работают очень быстро, что делает их подходящими для шифрования больших объемов данных, в частности файловых. Однако у алгоритмов симметричного шифрования есть одна слабая сторона: зашифрованный ими файл можно вскрыть, получив ключ. Если несколько человек собирается пользоваться одним файлом, защищенным только DESX, AES или 3DES, каждому из них понадобится доступ к FEK файла. Очевидно, что незашифрованный FEK — серьезная угроза безопасности. Ho шифрование FEK все равно не решает проблему, поскольку в этом случае нескольким людям приходится пользоваться одним и тем же ключом расшифровки FEK.
Защита FEK ~ сложная проблема, для решения которой EFS использует ту часть своей криптографической архитектуры, которая опирается на технологии шифрования с открытым ключом. Шифрование FEK на индивидуальной основе позволяет нескольким лицам совместно использовать зашифрованный файл. EFS может зашифровать FEK файла с помощью открытого ключа каждого пользователя и хранить их FEK вместе с файлом. Каждый может получить доступ к открытому ключу пользователя, но никто не сможет расшифровать с его помощью данные, зашифрованные по этому ключу. Единственный способ расшифровки файла заключается в использовании операционной системой закрытого ключа. Закрытый ключ помогает расшифровать нужный зашифрованный экземпляр FEK файла. Алгоритмы на основе открытого ключа обычно довольно медленные, поэтому они используются EFS только для шифрования FEK. Разделение ключей на открытый и закрытый немного упрощает управление ключами по сравнению с таковым в алгоритмах симметричного шифрования и решает дилемму, связанную с защитой FEK.
Windows хранит закрытые ключи в подкаталоге Application Data\Micro-soft\Crypto\RSA каталога профиля пользователя. Для защиты закрытых ключей Windows шифрует все файлы в папке RSA на основе симметричного ключа, генерируемого случайным образом; такой ключ
Функциональность EFS опирается на несколько компонентов, как видно на схеме архитектуры EFS (рис. 12–57). B Windows 2000 EFS реализована в виде драйвера устройства, работающего в режиме ядра и тесно связанного с драйвером файловой системы NTFS, но в Windows XP и Windows Server 2003 поддержка EFS включена в драйвер NTFS. Всякий раз, когда NTFS встречает шифрованный файл, она вызывает функции EFS, зарегистрированные кодом EFS режима ядра в NTFS при инициализации этого кода. Функции EFS осуществляют шифрование и расшифровку файловых данных по мере обращения приложений к шифрованным файлам. Хотя EFS хранит FEK вместе с данными файла, FEK шифруется с помощью открытого ключа индивидуального пользователя. Для шифрования или расшифровки файловых данных EFS должна расшифровать FEK файла, обращаясь к криптографическим сервисам пользовательского режима.
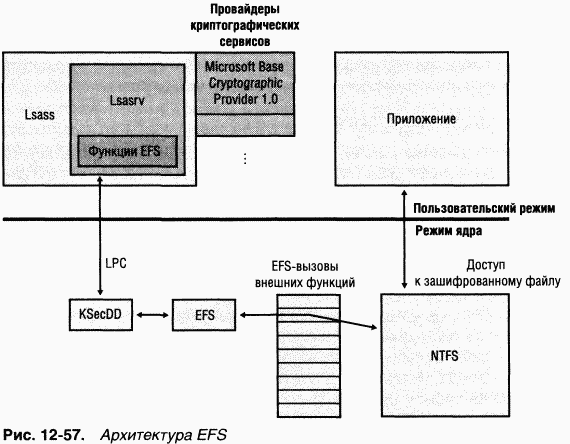 |
Подсистема локальной аутентификации (Local Security Authentication Subsystem, LSASS) (\Windows\System32\Lsass.exe) не только управляет сеансами регистрации, но и выполняет все рутинные операции, связанные с управлением ключами EFS. Например, когда драйверу EFS требуется расшифровать FEK для расшифровки данных файла, к которому обращается пользователь, драйвер EFS посылает запрос LSASS через LPC Драйвер устройства KSecDD (\Windows\System32\Drivers\Ksecdd.sys) экспортирует функции, необходимые драйверам для посылки LPC-сообщений LSASS. Компонент LSASS, сервер локальной аутентификации (Local Security Authentication Server, Lsasrv) (\Windows\System32\Lsasrv.dll), ожидает запросы на расшифровку FEK через RPC; расшифровка выполняется соответствующей функцией EFS, которая также находится в Lsasrv. Для расшифровки FEK, передаваемого LSASS драйвером EFS в зашифрованном виде, Lsasrv использует функции Microsoft CryptoAPI (CAPI).
CryptoAPI состоит из DLL провайдеров криптографических сервисов (cryptographic service providers, CSP), которые обеспечивают приложениям доступ к различным криптографическим сервисам (шифрованию, дешифрованию и хэшированию). Например, эти DLL управляют получением открытого и закрытого ключей пользователя, что позволяет Lsasrv не заботиться о деталях защиты ключей и даже об особенностях работы алгоритмов шифрования. EFS опирается на алгоритмы шифрования RSA, предоставляемые провайдером Microsoft Enhanced Cryptographic Provider (\Windows\ System32\Rsaenh.dll). Расшифровав FEK, Lsasrv возвращает его драйверу EFS в ответном LPC-сообщении. Получив расшифрованный FEK, EFS с помощью DESX расшифровывает данные файла для NTFS.
Подробнее о том, как EFS взаимодействует с NTFS и как Lsasrv управляет ключами через CryptoAPI, мы поговорим в следующих разделах.
Обнаружив шифрованный файл, драйвер NTFS вызывает функции EFS. O состоянии шифрования файла сообщают его атрибуты — так же, как и о состоянии сжатия в случае сжатых файлов. NTFS и EFS имеют специальные интерфейсы для преобразования файла из незашифрованной в зашифрованную форму, но этот процесс протекает в основном под управлением компонентов пользовательского режима. Как уже говорилось, Windows позволяет шифровать файлы двумя способами: утилитой командной строки
Получив RPC-сообщение с запросом на шифрование файла от Feclient, Lsasrv использует механизм олицетворения Windows для подмены собой пользователя, запустившего программу, шифрующую файл
Далее Lsasrv создает файл журнала в каталоге System Volume Information, где регистрирует ход процесса шифрования. Имя файла журнала — обычно EfsO.log, но, если шифруется несколько файлов, O заменяется числом, которое последовательно увеличивается на 1 до тех пор, пока не будет получено уникальное имя журнала для текущего шифруемого файла.
CryptoAPI полагается на информацию пользовательского профиля, хранящуюся в реестре, поэтому, если профиль еще не загружен, следующий шаг Lsasrv — загрузка в реестр профиля олицетворяемого пользователя вызовом функции
После этого Lsasrv генерирует для файла FEK, обращаясь к средствам шифрования RSA, реализованным в Microsoft Base Cryptographic Provider 1.0.
K этому моменту Lsasrv уже получил FEK и может сгенерировать информацию EFS, сохраняемую вместе с файлом, включая зашифрованную версию FEK. Lsasrv считывает из параметра реестра HKCU\Software\Microsoft\Win-dows NT\CurrentVersion\EFS\CurrentKeys\CertificateHash значение, присвоенное пользователю, который затребовал операцию шифрования, и получает сигнатуру открытого ключа этого пользователя. (Заметьте, что этот раздел не появляется в реестре, если ни один файл или каталог не зашифрован.) Lsasrv использует эту сигнатуру для доступа к открытому ключу пользователя и для шифрования FEK.
Теперь Lsasrv может создать информацию, которую EFS сохранит вместе с файлом. EFS хранит в шифрованном файле только один блок информации, в котором содержатся записи для всех пользователей этого файла. Данные записи называются
Формат данных EFS, сопоставленных с файлом, и формат элемента ключа показан на рис. 12–58. B первой части элемента ключа EFS хранит информацию, достаточную для точного описания открытого ключа пользователя. B нее входит SID пользователя (его наличие не гарантируется), имя контейнера, в котором хранится ключ, имя провайдера криптографических сервисов и хэш сертификата криптографической пары (при расшифровке используется только этот хэш). Bo второй части элемента ключа содержится шифрованная версия FEK. Lsasrv шифрует FEK через CryptoAPI по алгоритму RSA с применением открытого ключа данного пользователя.
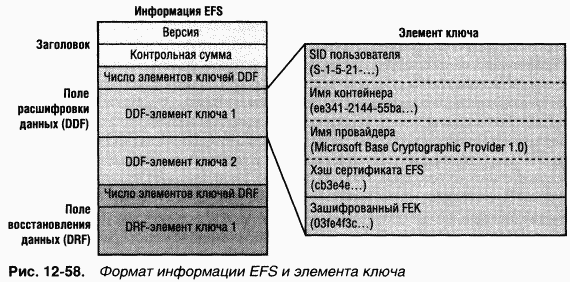 |
Далее Lsasrv создает еще одну связку ключей, содержащую элементы ключей восстановления (recovery key entries). EFS хранит информацию об этих элементах в поле DRF файла (см. рис. 12–58). Формат элементов DRF идентичен формату DDE DRF служит для расшифровки пользовательских данных по определенным учетным записям (агентов восстановления) в тех случаях, когда администратору нужен доступ к пользовательским данным. Допустим, сотрудник компании забыл свой пароль для входа в систему. B этом случае администратор может сбросить пароль этого сотрудника, но без агентов восстановления никто не сумеет восстановить его зашифрованные данные.
Агенты восстановления (Recovery Agents) определяются в политике безопасности Encrypted Data Recovery Agents (Агенты восстановления шифрованных данных) на локальном компьютере или в домене. Эта политика доступна через оснастку Group Policy (Групповая политика) консоли MMC Запустите Recovery Agent Wizard (Мастер добавления агента восстановления), щелкнув правой кнопкой мыши строку Encrypted Data Recovery Agents (рис. 12–59) и последовательно выбрав команды New (Создать) и Encrypted Recovery Agent (Агент восстановления шифрованных данных). Вы можете добавить агенты восстановления и указать, какие криптографические пары (обозначенные их сертификатами) могут использовать эти агенты для восстановления шифрованных данных. Lsasrv интерпретирует политику восстановления в процессе своей инициализации или при получении уведомления об изменении политики восстановления. EFS создает DRF-элементы ключей для каждого агента восстановления, используя провайдер криптографических сервисов, зарегистрированный для EFS-восстановления. Провайдером по умолчанию служит Base Cryptographic Provider 1.0.
 |
Ha завершающем этапе создания информации EFS для файла Lsasrv вычисляет контрольную сумму для DDF и DRF по механизму хэширования MD5 из Base Cryptographic Provider 1.0. Lsasrv хранит вычисленную контрольную сумму в заголовке данных EFS. EFS ссылается на эту сумму при расшифровке, чтобы убедиться в том, что сопоставленные с файлом данные EFS не повреждены и не взломаны.
Ход процесса шифрования показан на рис. 12–60. После создания всех данных, необходимых для шифруемого пользователем файла, Lsasrv приступает к шифрованию файла и создает его резервную копию, Efs0.tmp (если есть другие резервные копии, Lsasrv просто увеличивает номер в имени резервного файла). Резервная копия помещается в тот каталог, где находится шифруемый файл. Lsasrv применяет к резервной копии ограничивающий дескриптор защиты, так что доступ к этому файлу можно получить только по учетной записи System. Далее Lsasrv инициализирует файл журнала, созданный им на первом этапе процесса шифрования и регистрирует в нем факт создания резервного файла. Lsasrv шифрует исходный файл только после его резервирования.
Наконец, Lsasrv посылает через NTFS коду EFS режима ядра команду на добавление к исходному файлу созданной информации EFS. B Windows 2000 NTFS получает эту команду, но поскольку она не понимает команд EFS, то просто вызывает драйвер EFS. Код EFS режима ядра принимает посланные Lsasrv данные EFS и применяет их к файлу через функции, экспортируемые NTFS. Эти функции позволяют EFS добавлять к NTFS-файлам атрибут $EFS. После этого управление возвращается к Lsasrv, который копирует содержимое шифруемого файла в резервный. Закончив создание резервной копии (в том числе скопировав все дополнительные потоки данных), Lsasrv отмечает в файле журнала, что резервный файл находится в актуальном состоянии. Затем Lsasrv посылает NTFS другую команду, требуя зашифровать содержимое исходного файла.
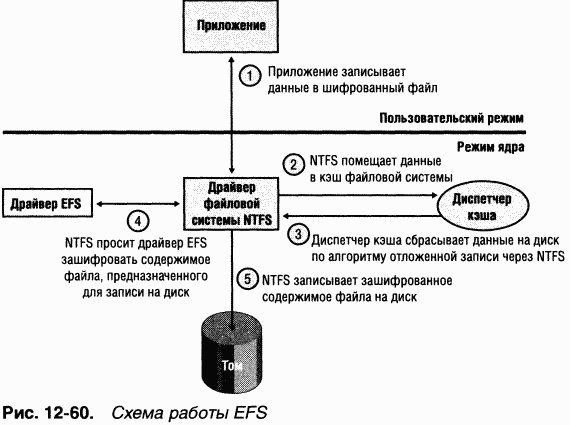 |
Получив от EFS команду на шифрование файла, NTFS удаляет содержимое исходного файла и копирует в него данные резервного. По мере копирования каждого раздела файла NTFS сбрасывает данные раздела из кэша файловой системы, и они записываются на диск. Поскольку файл помечен как шифрованный, NTFS вызывает EFS для шифрования раздела данных перед записью на диск. EFS использует незашифрованный FEK, переданный NTFS, чтобы шифровать файловые данные по алгоритму DESX, AES или 3DES порциями, равными по размеру одному сектору (512 байтов).
После того как файл зашифрован, Lsasrv регистрирует в файле журнала, что шифрование успешно завершено, и удаляет резервную копию файла. B заключение Lsasrv удаляет файл журнала и возвращает управление приложению, запросившему шифрование файла.
Ниже приведен сводный список этапов шифрования файла через EFS.
1. Загружается профиль пользователя, если это необходимо.
2. B каталоге System Volume Information создается файл журнала с именем Efsxlog, где
3. Base Cryptographic Provider 1.0 генерирует для файла случайное 128-битное число, используемое в качестве FEK.
4. Генерируется или считывается криптографическая пара ключей пользователя. Она идентифицируется в HKCU\Software\Microsoft\Windows NT\ CurrentVersion\EFS\CurrentKeys\CertificateHash.
5. Для файла создается связка ключей DDF с элементом для данного пользователя. Этот элемент содержит копию FEK, зашифрованную с помощью открытого EFS-ключа пользователя.
6. Для файла создается связка ключей DRF B нем есть элементы для каждого агента восстановления в системе, и при этом в каждом элементе содержится копия FEK, зашифрованная с помощью открытого EFS-ключа агента.
7. Создается резервный файл с именем вида Efs0.tmp в том каталоге, где находится и шифруемый файл.
8. Связки ключей DDF и DRF добавляются к заголовку и сопоставляются с файлом как атрибут EFS.
9. Резервный файл помечается как шифрованный, и в него копируется содержимое исходного файла.
10. Содержимое исходного файла уничтожается, в него копируется содержимое резервного. B результате этой операции данные исходного файла шифруются, так как теперь файл помечен как шифрованный.
11. Удаляется резервный файл.
12. Удаляется файл журнала.
13. Выгружается профиль пользователя (загруженный на этапе 1).
При сбое системы во время шифрования согласованные данные непременно сохранятся в одном из файлов — исходном или резервном. Когда Lsasrv инициализируется после сбоя системы, он ищет файлы журнала в каталоге System Volume Information на каждом NTFS-томе в системе. Если Lsasrv находит один или несколько файлов журнала, он изучает их содержимое и определяет порядок восстановления. Если исходный файл не был модифицирован на момент аварии, Lsasrv удаляет файл журнала и соответствующий резервный файл; в ином случае он копирует резервный файл поверх исходного (частично шифрованного) файла, после чего удаляет журнал и резервную копию. После того как Lsasrv обработает файлы журналов, файловая система возвращается в целостное состояние без потери пользовательских данных.
Процесс расшифровки начинается, когда пользователь открывает шифрованный файл. При открытии файла NTFS анализирует его атрибуты и выполняет функцию обратного вызова в драйвере EFS. Драйвер EFS считывает атрибут $EFS, сопоставленный с шифрованным файлом. Чтобы прочитать этот атрибут, драйвер вызывает функции поддержки EFS, которые NTFS экспортирует для EFS. NTFS выполняет все необходимые действия, чтобы открыть файл. Драйвер EFS проверяет наличие у пользователя, открывающего файл, прав доступа к данным шифрованного файла (т. е. зашифрованный FEK в связке ключей DDF или DRF должен соответствовать криптографической паре ключей, сопоставленной с пользователем). После такой проверки EFS получает расшифрованный FEK файла, применяемый для обработки данных в операциях, которые пользователь может выполнять над файлом.
EFS не может расшифровать FEK самостоятельно и полагается в этом на Lsasrv (который может использовать CryptoAPI). C помощью драйвера Ksecdd.sys EFS посылает LPC-сообщение Lsasrv, чтобы тот извлек из атрибута IEFS (т. е. из данных EFS) FEK пользователя, открывающего файл, и расшифровал его.
Получив LPC-сообщение, Lsasrv вызывает функцию
Lsasrv, обрабатывая при расшифровке FEK связки ключей DDF и DRF, автоматически выполняет операции восстановления файла. Если к файлу пытается получить доступ агент восстановления, не зарегистрированный на доступ к шифрованному файлу (т. е. у него нет соответствующего поля в связке ключей DDF), EFS позволит ему обратиться к файлу, потому что агент имеет доступ к паре ключей для поля ключа в связке ключей DRE
Путь от драйвера EFS до Lsasrv и обратно требует довольно много времени — в процессе расшифровки FEK в типичной системе CryptoAPI использует результаты более 2000 вызовов API-функций реестра и 400 обращений к файловой системе. Чтобы сократить издержки от всех этих вызовов, драйвер EFS использует кэш в паре с NTFS.
Открыв шифрованный файл, приложение может читать и записывать его данные. Для расшифровки файловых данных NTFS вызывает драйвер EFS по мере чтения этих данных с диска — до того, как помещает их в кэш файловой системы. Аналогичным образом, когда приложение записывает данные в файл, они остаются незашифрованными в кэше файловой системы, пока приложение или диспетчер кэша не сбросит данные обратно на диск с помощью NTFS. При записи данных шифрованного файла из кэша на диск NTFS вызывает драйвер EFS, чтобы зашифровать их.
Как уже говорилось, драйвер EFS выполняет шифрование и расшифровку данных порциями по 512 байтов. Такой размер оптимален для драйвера, потому что объем данных при операциях чтения и записи кратен размеру сектора.
Важный аспект разработки любого механизма шифрования файлов заключается в том, что приложения не могут получить доступ к расшифрованным данным иначе, чем через механизмы шифрования. Это ограничение особенно важно для утилит резервного копирования, с помощью которых файлы сохраняются на архивных носителях. EFS решает эту проблему, предоставляя утилитам резервного копирования механизм, с помощью которого они могут создавать резервные копии файлов и восстанавливать их в шифрованном виде. Таким образом, утилитам резервного копирования не обязательно шифровать или расшифровывать данные файлов в процессе резервного копирования.
Для доступа к шифрованному содержимому файлов утилиты резервного копирования в Windows используют новый EFS APL функции
ЭКСПЕРИМЕНТ: просмотр информации EFS
EFS поддерживает массу других API-функций, с помощью которых приложения могут манипулировать шифрованными файлами. Так, функция
B качестве параметра ее командной строки указано имя шифрованного файла.
 |
Как видите, в файле test.txt имеется один элемент DDF, соответствующий пользователю Mark, и один элемент DRF, соответствующий Administrator, который является единственным агентом восстановления, зарегистрированным в системе на данный момент.
Чтобы убедиться в наличии атрибута $EFS в зашифрованном файле, используйте утилиту Nfi из OEM Support Tools:
 |
Windows поддерживает широкий спектр форматов файловых систем, доступных как локальной системе, так и удаленным клиентам. Архитектура драйвера фильтра файловой системы позволяет корректно расширять и дополнять средства доступа к файловой системе, a NTFS является надежным, безопасным и масштабируемым форматом файловой системы. B следующей главе мы рассмотрим поддержку сетей в Windows.
(support [a t] reallib.org)